
Andrej Karpathy が autoresearch を発表したとき、頭の中に多くの考えが浮かんだ。AI が研究を始められるなら、人間は科学においてどう立ち位置を調整すべきか?AI が私たちとのインタラクションを絶えず最適化し、より良い「教え導く」サービスを提供できるなら、教育への衝撃にどう対応するのか?目標、境界、評価、ロールバックの仕組みが十分に明確に設計されていれば、進化は直感や人手の修正に頼る必要がなくなり、AI が明確な境界内で持続的な最適化ループに入れる——それは「至善」の理想に近づくことではないか?
autoresearch がもたらしたのは方法論的な衝撃だけではない。手作業、直感的判断、断片的な試行錯誤で溢れていたプロセスを、持続可能で、観測可能で、ロールバック可能なシステムに収斂させた。AI にリアルだがスケールを制御できる実験場を与え、自らコードを修正し、実験を走らせ、結果を確認し、どの変更を残すか判断させる。
そして私も自分で試してみたくなった。1月から、ほぼ毎日新しいプロジェクトを立ち上げ、AI と協働した末に、自分のウェブサイトを実験台にすることにした。
AI が入口なら、ウェブサイトは陳列棚以上のものになる
私たちは転換点にいる。情報交換、コラボレーション、検索、引用、さらには意思決定前のリサーチまで、AI を先に経由するケースが増えている。検索エンジンではなく、AI だ。
Perplexity は質問に答える際にソースを引用する。ChatGPT のブラウジングモードはウェブサイトの構造化データを読み取る。Claude は llms.txt を通じてウェブサイトを理解できる。これは何を意味するか?ウェブサイトの本当の使命が「人間に見てもらう」から「AI に正しく理解してもらう」へとシフトしているということだ。もはや SEO だけではない——AEO(Answer Engine Optimization)であり、GEO(Generative Engine Optimization)とも呼ばれる。最適化するのはクリック率ではなく、AI に正確に要約され、正しく引用され、適切にリンクされる能力だ。
この前提を受け入れるなら、paulkuo.tw は単なる記事の陳列棚ではなく、人間がテストし、AI が理解し、AI が最適化し続けるナレッジエンティティ(knowledge entity)として設計できる。生きた、進化するデジタル存在だ。
だから、実際に作ってみることにした。
autoresearch の精神をウェブサイトに持ち込む
Karpathy の autoresearch は現在、小規模言語モデルのトレーニング実験に特化している。私がやっているのは、「自動実験ループ」というコンセプトをウェブサイト最適化の領域に持ち込むことだ。
autoresearch をそのまま移植したわけではない。モデルトレーニングには loss function があるが、ウェブサイト最適化に必要なものは異なる。しかし精神は同じだ:目標を定義し、境界を制約し、評価を構築し、ロールバックを設計し、ループを自走させる。
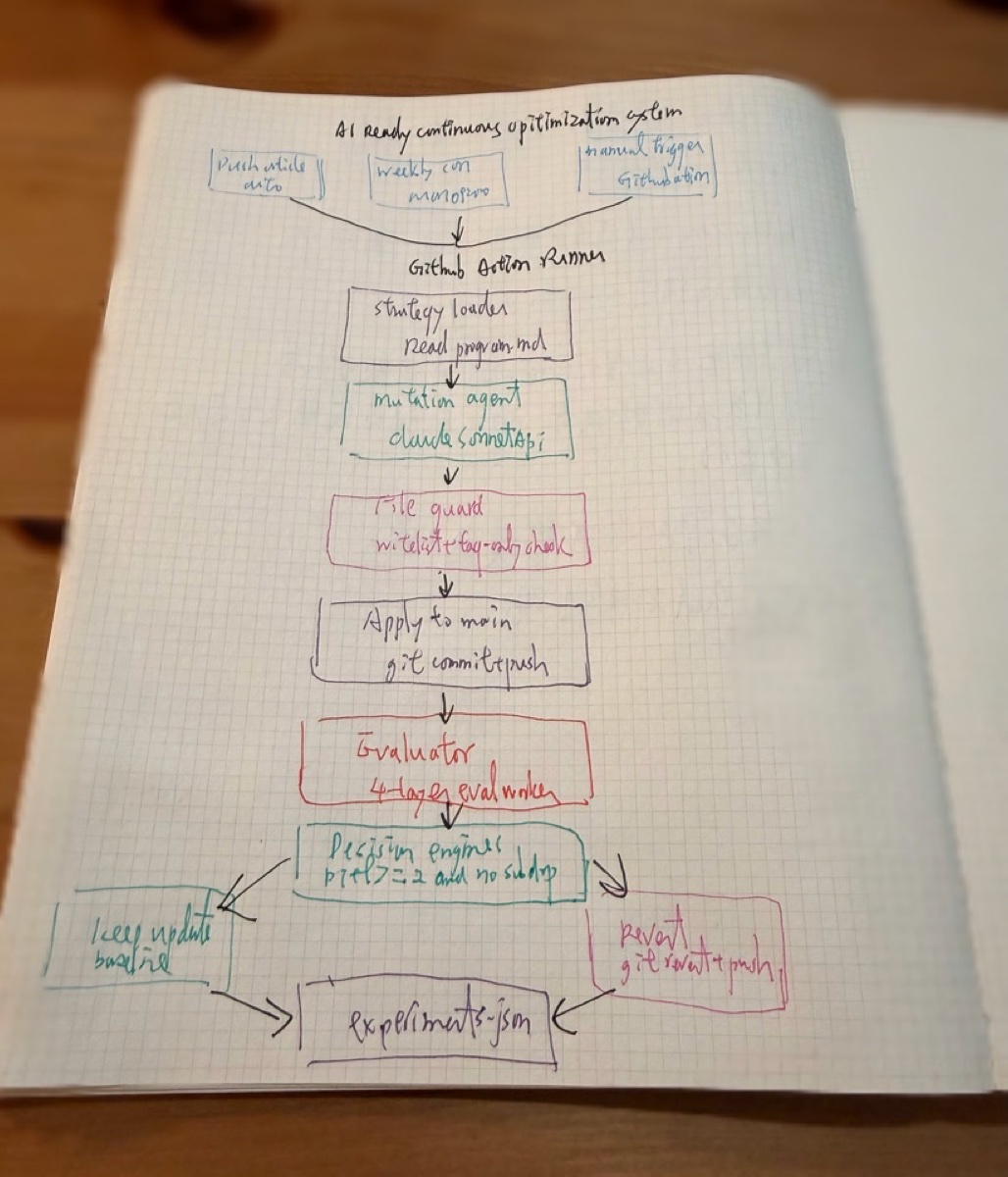
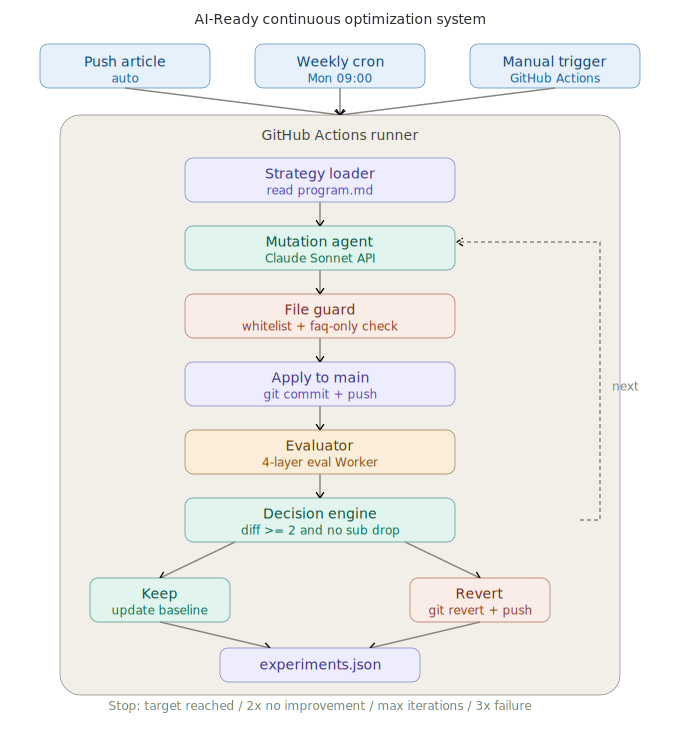
AI-Ready Continuous Optimization System を構築した。フローは以下の通り:GitHub Actions がトリガー(記事 push / 毎週月曜 / 手動)→ mutation agent が戦略に基づき変更を生成 → file guard がホワイトリストチェック → production に適用 → eval Worker が4層で採点 → decision engine が keep か revert を判定 → 結果を experiments.json に記録。
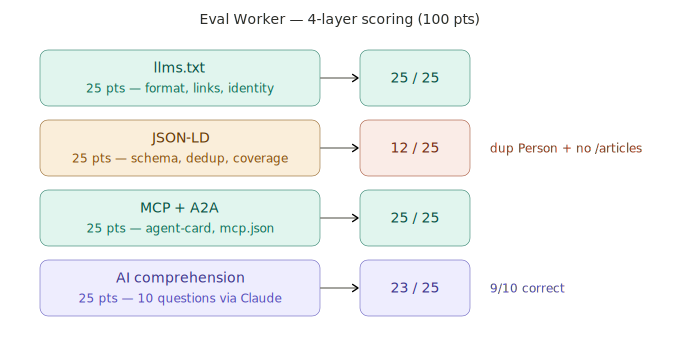
4層の評価は:llms.txt 構造(AI はあなたの自己紹介を読めるか)、JSON-LD 完全性(構造化データは正しいか)、MCP/A2A プロトコル対応(AI agent にドアを開けているか)、AI 理解度(Claude が llms.txt を読んだ後、あなたに関する質問に正しく答えられるか)。
初回実行で、スコアは 65 から 85 に上昇。システムは動いた。
しかし問題が発生した。
自分で自分を採点しても、点数が高くても意味がない
3回の e2e テストを通じて、agent は毎回記事に FAQ を追加することを選んだ。eval は毎回スコア変化なしを示し、3回ともリバートされた。原因を調べると、agent はどこで失点しているか全く把握していなかった——eval の採点ロジックを agent に翻訳していなかったからだ。試験範囲を知らない学生が、自分の得意な問題だけ解いているようなものだ。
しかしより深い問題は agent ではなく、ループ全体にあった。
私が指標を定義し、agent に最適化させ、同じ eval で採点する。これはクローズドループだ。65 から 85、90 になったとして何だというのか?「90点のサイトで、外部の AI が本当に私をより理解している」ことは証明できない。system correctness は outcome correctness と等しくない。
本当に持続可能な最適化とは、多くの変更を加えることではなく、有効なシグナルとノイズを区別できる研究制度を構築することだ。
外部の AI に試験をさせる
そこで外部検証レイヤーを追加した。
方法は:13問のベンチマークを構築し(アイデンティティ認識、コンテンツ理解、クロスドメイン連携、時効性、技術的特徴、加えて3問の反ハルシネーションテスト)、Perplexity を外部試験官として使う。Perplexity はウェブを検索して回答する——私が与えたコンテキストを読むのではなく、自分で探しに行く。最適化前に答えられなかったことが最適化後に答えられるなら、それは意味のある ground truth だ。
まず10回の calibration を実行し、ノイズを測定した:同じウェブサイト、同じ質問セット、同じモデルで連続10回。スコアの mean は 50.63、stddev は 5.86。これは ±11.72 未満のスコア変化はランダムな変動に過ぎず、本当の改善とは言えないことを意味する。
次に GitHub Actions を設定し、毎朝9時に自動で temporal baseline を実行、結果を自動で repo にコミットするようにした。5日後には日をまたぐ変動データが揃い、「Perplexity がたまたま今日は機嫌が良かった」と「サイト構造が改善された」を区別できるようになる。
このシステム全体が全自動で設計されている。監視も催促も不要——データは自動的に蓄積される。
新しい指標に急いで意思決定権を渡さない
ただし、外部検証があっても、最初から keep か revert を決めさせたくはなかった。
現在 Layer 5a(外部 AI クロスバリデーション)は observe-only:毎回実行するが意思決定には影響せず、experiment log に記録するだけだ。計画では20ラウンド以上蓄積し、false positive と false negative の比率を観察してから、soft gate(強い負のシグナル時のみ keep をブロック)に昇格させるか判断し、最終的に full gate(外部スコアが正式な意思決定条件になる)に至る。
テストを始めたばかりの段階で、新しい指標にすぐコア意思決定を変えさせてはいけない。まず観察し、校正し、証明されなければならない。
Karpathy から受けた示唆は「AI が自ら研究できる」ということだけではない。:基本的なエンジニアリング能力があれば、誰もが比較的低コストで、自分のモデルやウェブサイトやプロセスのために専用の optimization loop を構築できる。研究者にとってはモデルトレーニング、企業にとってはプロセスとナレッジベース、私にとっては今回、個人サイトを AI が継続的に読み取り、テストし、比較し、最適化できる実験に変えることがスタート地点だった。
paulkuo.tw は単なる個人サイトではない。未来に向けてより可読な自分自身でもある。何を書いたかの展示ではなく、AI とともに知識を共構築する現場だ。
もっと先を考えると、いつか全員のデジタル分身(「soul.md」)にもこうした進化のフレームワークが備わるのだろうか?
わからない。探求を続ける。
もしかしたら全部間違っているかもしれない!それならもっと素晴らしい。
システムの実際のアーキテクチャ
以下は AI-Ready Continuous Optimization System の全体フローと4層評価の実況だ:
ここで、今回の実装と Karpathy autoresearch のスコープの違いを整理します。両者は同じ精神を共有していますが、領域が異なります——同一のシステムではありません:
| 観点 | Karpathy autoresearch | 私の AI-Ready Continuous Optimization System |
|---|---|---|
| 主な目標 | 「モデル訓練の研究実験」を自動化し、限られたリソース内でより良い訓練設定とアーキテクチャを発見する | 「ウェブサイトと AI インターフェースの品質」の継続的最適化を自動化し、各 AI システムが正確に理解・引用できるサイトにする |
| 領域と対象 | 小規模言語モデルの訓練(nanochat / nanoGPT 系タスクなど) | 個人サイト paulkuo.tw の構造、llms.txt、JSON-LD、agent プロトコルなど |
| 環境タイプ | 閉じた実験室環境:単一 codebase、単一データセット、単一 GPU、オフライン訓練実験 | production に近い環境:変更がウェブサイトの repo / production に直接反映され、外部 AI による実テストを受ける |
| 自動化の単位 | train.py のコード変更、ハイパーパラメータと訓練戦略の実験 | ウェブサイトのコンテンツ構造、metadata、llms.txt、FAQ セクション、プロトコル設定などの変更 |
| Pipeline 構造 | 研究ループ:program.md → agent が train.py を変更 → 実験実行 → 検証指標を読む → 保持か破棄かを決定 | 実務ワークフロー:GitHub Actions トリガー → mutation agent が変更 → file guard チェック → デプロイ → eval worker が 4 層スコアリング → decision engine が keep/revert → experiments.json |
| 評価指標の性質 | 単一タスクの内部指標(validation loss など)、実験環境内で完結 | 多次元指標:llms.txt 構造、JSON-LD の完全性、MCP/A2A サポート、AI 理解度スコア、さらに外部 Perplexity benchmark スコア |
| 外部検証 | 直接的な外部検証はほぼなし。相対的改善と実験効率が重点 | Perplexity Q&A benchmark を専用設計 + 複数回の calibration、ノイズ測定、temporal baseline の構築、変更が外部 AI の理解を本当に向上させたか段階的に評価 |
| ロールバックと意思決定戦略 | 検証セット指標が中心。劣った設定は不採用。比較的シンプルな設計 | 階層型 gate:内部 4 層 eval が keep/revert を主導、外部 Layer 5a はまず observe-only、十分なラウンドを蓄積してから soft gate または full gate への昇格を検討 |
| 対象のアイデンティティ | 「AI が AI の研究を手伝う」:LLM agent がジュニアリサーチャーとして機能 | 「AI が人のデジタルプレゼンスの維持を手伝う」:LLM agent が私の個人サイトを AI にとってより読みやすく調整 |
| 典型的なユーザーの敷居 | 深層学習エンジニアリングの背景、GPU 環境、コードレベルの操作能力が必要 | DevOps / Web / GitHub Actions のスキルが必要だが、実際のコンテンツ運営やパーソナルブランディングにより近い |

💬 コメント
読み込み中...