
看到 Andrej Karpathy 发布 autoresearch 时,脑子里闪过很多念头。当 AI 可以开始做研究,人类在科研中的位置该怎么调整?AI 可以不断优化与我们的交互,提供更好的”传道授业解惑”服务,我们要怎么应对教育的冲击?如果一个系统的目标、边界、评估与回滚机制都设计得足够清晰,进化可以不依赖直觉与人为修改,而是靠 AI 在明确边界内进入持续优化循环,我们是否就更接近”止于至善”的理想?
autoresearch 带来的不只是方法论上的震撼,它把充满手工操作、直觉判断与零散试错的事情,收敛成了一个可持续循环、可被观测、也可以被回滚的系统。给 AI 一个足够真实但规模可控的实验场,让它自己修改、自己跑、自己看结果,再决定哪些变更值得保留。
然后我就想自己动手试试。从一月起,几乎每天都开新的项目,跟 AI 协作之后,决定用自己的网站做实验。
如果 AI 是入口,网站就不只是展示架
我们正进入一个转折点:越来越多的信息交流、协作、搜索、引用、甚至决策前的调研,都先经过 AI。不是搜索引擎,是 AI。
Perplexity 回答问题的时候会引用来源,ChatGPT 的浏览模式会抓取网站结构化数据,Claude 可以通过 llms.txt 理解网站。这意味着什么?意味着一个网站真正的任务,正在从”被人看到”转向”被 AI 正确理解”。不只是 SEO,而是 AEO(Answer Engine Optimization)——也有人叫 GEO(Generative Engine Optimization)。你优化的不是点击率,而是被 AI 正确摘要、正确引用、正确链接的能力。
接受这个前提的话,那 paulkuo.tw 就不只是我的文章展示架,而可以被设计成一个持续被人类测试、被 AI 理解、被 AI 优化的知识实体(knowledge entity),一个活的、进化的数字存在。
所以我就试着做了起来。
把 autoresearch 的精神搬到网站上
Karpathy 的 autoresearch 目前专注在小型语言模型的训练实验上,我这里是把“自动实验循环”这个概念搬到网站优化领域。
我不是把 autoresearch 原封不动搬过来。模型训练有 loss function,网站优化需要的是不同的东西。但精神是一样的:定义目标、限定边界、建立评估、设计回滚,然后让循环自己跑。
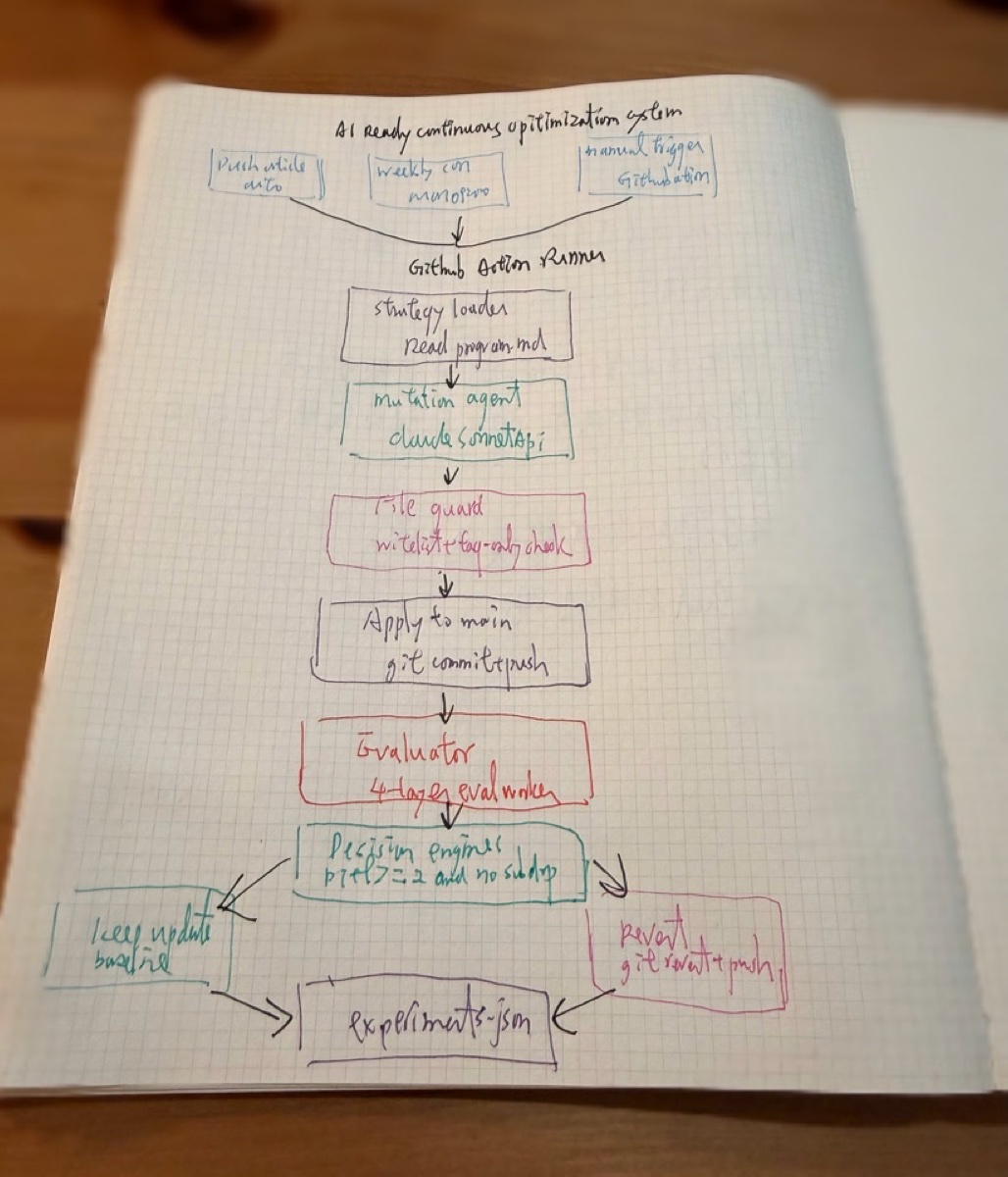
我搭建了一套 AI-Ready Continuous Optimization System。流程是这样的:GitHub Actions 触发(push 文章 / 每周一 / 手动)→ mutation agent 根据策略生成修改 → file guard 做白名单检查 → 应用到 production → eval Worker 四层评分 → decision engine 决定 keep 还是 revert → 结果写入 experiments.json。
四层评分分别看:llms.txt 结构(AI 读得懂你的自我介绍吗)、JSON-LD 完整性(结构化数据对不对)、MCP/A2A 协议支持(你有没有为 AI agent 开门)、AI 理解度(Claude 读完你的 llms.txt 之后,能正确回答关于你的问题吗)。
第一轮跑完,分数从 65 拉到 85。系统跑通了。
但问题来了。
自己考自己,分数再高也不算数
三轮 e2e 跑下来,agent 每次都选择给文章加 FAQ,eval 每次都显示分数不变,三轮全部 revert。我去查原因,发现 agent 根本不知道分数从哪丢的——因为我没把 eval 的计分逻辑翻译给它看。它就像一个不知道考试范围的学生,只会做自己最拿手的题目。
但更深层的问题不在 agent,在整个循环本身。
我自己定义指标、让 agent 优化、再用同一套 eval 回头打分。这是闭环。分数从 65 到 85 到 90 又怎样?我没办法证明”90 分的网站,外部的 AI 真的更懂我”。system correctness 不等于 outcome correctness。
真正可持续的优化,不是做很多修改,而是建立一套能区分有效信号与无效波动的研究制度。
让外部 AI 来考
所以我加了一层外部验证。
做法是:建立 13 题 benchmark(涵盖身份识别、内容理解、跨域关联、时效性、技术特色,还有 3 题反幻觉测试),用 Perplexity 当外部考官。Perplexity 会搜索网络再回答,不是读我喂的 context,而是自己去找。如果它优化前答不出来、优化后答得出来,那就是有意义的 ground truth。
先跑了 10 次 calibration,测量噪声:同一个网站、同一组题目、同一个模型,连续问 10 次,分数的 mean 是 50.63,stddev 是 5.86。这意味着任何小于 ±11.72 的分数变化,都可能只是随机波动,不算真正的改善。
然后设了 GitHub Actions,每天早上 9 点自动跑一次 temporal baseline,结果自动 commit 回 repo。五天之后,我就有跨天的波动数据,可以区分”Perplexity 今天心情好所以分数高”和”网站结构改善所以分数高”。
这整套系统设计成全自动。不用去盯去催,数据自己积累。
不急着让新指标主导决策
不过,即使有了外部验证,我也不想一开始就让它决定 keep 还是 revert。
目前 Layer 5a(外部 AI 交叉验证)是 observe-only:每轮都跑,但不影响决策,只记录到 experiment log。我的规划是积累 20 轮以上,观察 false positive 和 false negative 的比率,之后再决定要不要升级成 soft gate(只在强烈负向时阻止 keep),再到 full gate(外部分数成为正式决策条件)。
刚开始做测试,不能让新指标一接进来就改变核心决策。它必须先被观察、被校准、被证明。
Karpathy 给我的启发,不只是”AI 可以自己做研究”,而是:只要有基本工程能力,每个人都可以用相对低成本,为自己的模型、网站或流程,建立一个专属的 optimization loop。对研究者来说是模型训练,对企业来说是流程与知识库,对我来说,这次的起点是把我的个人网站变成一个可以被 AI 持续读取、测试、比较与优化的实验。
paulkuo.tw 不只是我的个人网站,也是一个面向未来更可读的自己。不只是我写过什么的展示,而是我如何与 AI 共同构建知识的现场。
想得更远一点,未来,每个人的数字分身(“soul.md”)都会有这样的进化框架吗?
不知道。继续探寻。
也许我想错了!那更棒。
系统实际架构
以下是 AI-Ready Continuous Optimization System 的完整流程与四层评分实况:
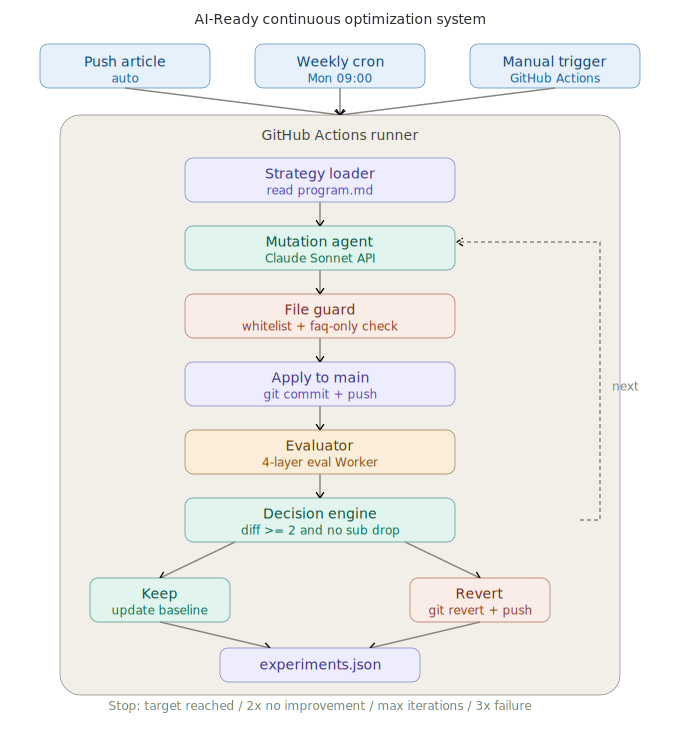
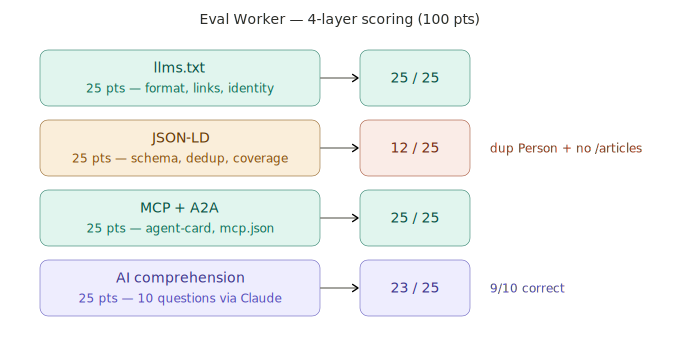
下面整理我这次实作与 Karpathy autoresearch 的范围差异,两者精神相近但领域不同,不是同一种系统:
| 面向 | Karpathy autoresearch | 我的 AI-Ready Continuous Optimization System |
|---|---|---|
| 主要目标 | 自动化「模型训练研究实验」,在固定资源内找到更好的训练设定与架构 | 自动化「网站与 AI 接口质量」的持续优化,让网站更容易被各家 AI 正确理解与引用 |
| 领域与对象 | 小型语言模型训练(例如 nanochat / nanoGPT 类任务) | 个人网站 paulkuo.tw 的结构、llms.txt、JSON-LD、agent 协议等 |
| 环境类型 | 封闭实验室环境:单一 codebase、单一数据集、单 GPU,离线训练实验 | 接近 production:修改直接作用在网站 repo / production,并接受外部 AI 的实测 |
| 自动化单位 | 针对 train.py 的代码修改、超参数与训练策略实验 | 针对网站内容结构、metadata、llms.txt、FAQ 区块、协议设定等进行修改 |
| Pipeline 结构 | 研究 loop:program.md → agent 改 train.py → 跑实验 → 读验证指标 → 决定保留或丢弃 | 实务 workflow:GitHub Actions 触发 → mutation agent 修改 → file guard 检查 → 部署 → eval worker 四层评分 → decision engine keep/revert → experiments.json |
| 评估指标性质 | 单一任务内部指标(例如 validation loss),完全在实验环境内产生与使用 | 多维指标:llms.txt 结构、JSON-LD 完整度、MCP/A2A 支持、AI 理解度,再加外部 Perplexity benchmark 分数 |
| 外部验证 | 几乎没有直接外部世界验证,重点是相对改进和实验效率 | 额外设计 Perplexity 问答 benchmark + 多次 calibration,测量噪音、建立 temporal baseline,逐步评估改动是否真的提升外部 AI 的理解 |
| 回滚与决策策略 | 以验证集指标为主,较差设定不采用,设计较简单 | 分层 gate:内部四层 eval 主导 keep/revert,外部 Layer 5a 先 observe-only,累积足够轮数后才考虑升级为 soft gate 或 full gate |
| 对象身份 | 「AI 帮 AI 做研究」:LLM agent 充当 junior researcher | 「AI 帮人维护数字存在」:LLM agent 帮我调整个人网站,让它对 AI 更可读 |
| 典型用户门槛 | 需要深度学习工程背景、GPU 环境与代码操作能力 | 需要 DevOps / Web / GitHub Actions 能力,但更贴近实际内容运营与个人品牌 |

💬 留言讨论
加载中...