
When I saw Andrej Karpathy release autoresearch, many thoughts flashed through my mind. When AI can start doing research, how should humans adjust their position in scientific research? AI can continuously optimize interactions with you and me, providing better “teaching and guidance” services—how should we respond to the impact on education? If a system’s goals, boundaries, evaluation, and rollback mechanisms are all designed clearly enough, evolution doesn’t need to rely on intuition and manual modifications but can have AI enter a continuous optimization loop within clear boundaries. Are we then closer to the ideal of “reaching ultimate perfection”?
autoresearch brings more than just methodological shock—it converges work filled with manual operations, intuitive judgments, and fragmented trial-and-error into a sustainable, observable, and rollback-capable system. Give AI a realistic but controllably-sized experimental ground, let it modify itself, run itself, see the results itself, then decide which changes are worth keeping.
Then I wanted to test it myself. Since January, I’ve started new projects almost every day. After interacting with AI, I decided to use my own website as an experiment.
If AI is the Gateway, Websites Are More Than Display Cases
We’re entering a turning point: increasingly, information exchange, collaboration, search, citation, and even pre-decision research all go through AI first. Not search engines—AI.
Perplexity cites sources when answering questions, ChatGPT’s browsing mode extracts website structured data, Claude can understand websites through llms.txt. What does this mean? It means a website’s real mission is shifting from “being seen by humans” to “being correctly understood by AI.” Not just SEO, but AEO (Answer Engine Optimization)—some call it GEO (Generative Engine Optimization). You’re not optimizing click-through rates, but the ability to be correctly summarized, correctly cited, and correctly linked by AI.
If we accept this premise, then paulkuo.tw is not just my article display case, but can be designed as a knowledge entity that is continuously tested by humans, understood by AI, and optimized by AI—a living, evolving digital existence.
So I decided to try it.
Bringing autoresearch’s Spirit to Websites
Karpathy’s autoresearch currently focuses on small language model training experiments. Here, I’m transplanting the concept of “automated experimental loops” to the website optimization domain.
I’m not moving autoresearch over unchanged. Model training has loss functions; website optimization needs different things. But the spirit is the same: define goals, constrain boundaries, establish evaluation, design rollback, then let the loop run itself.
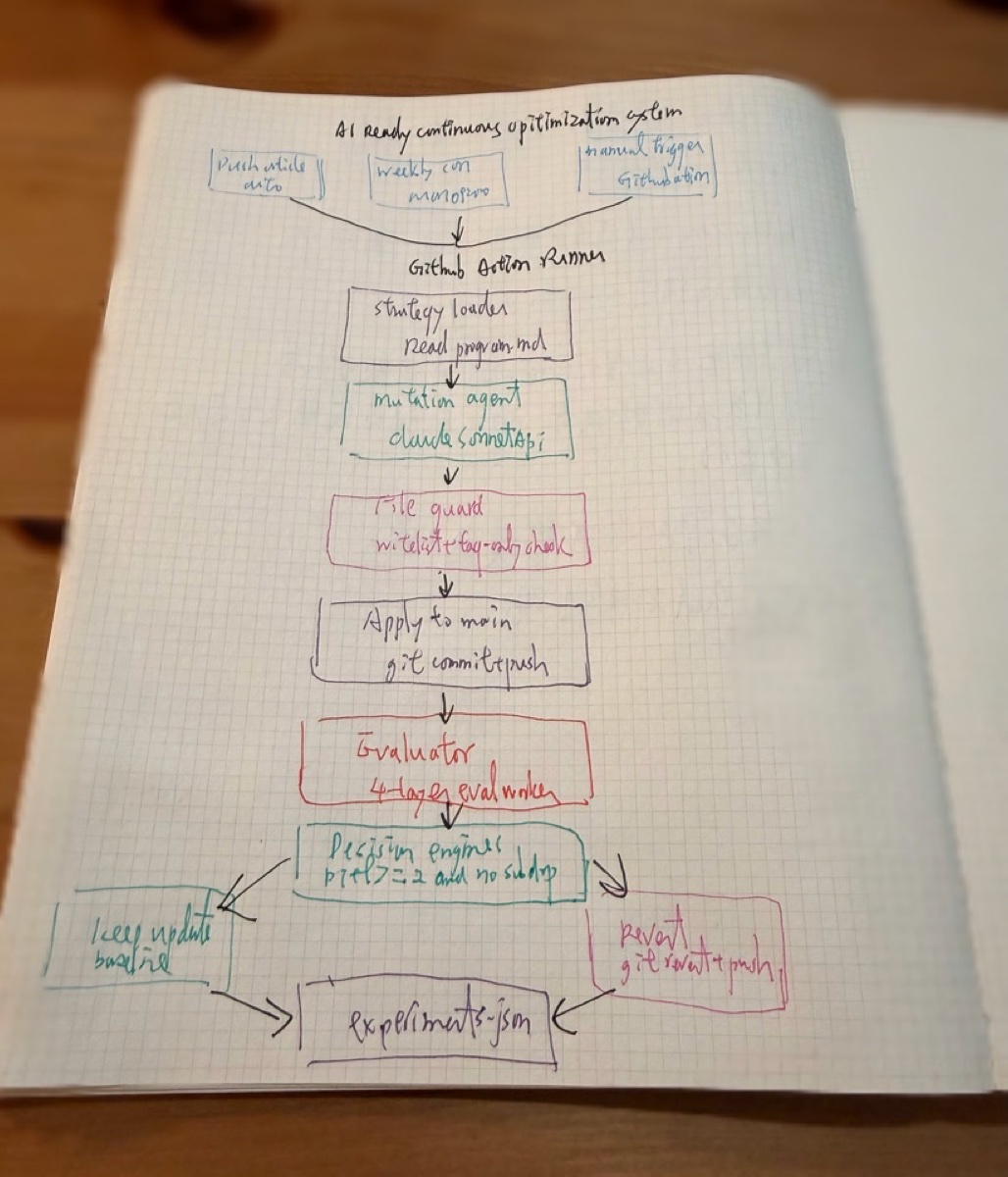
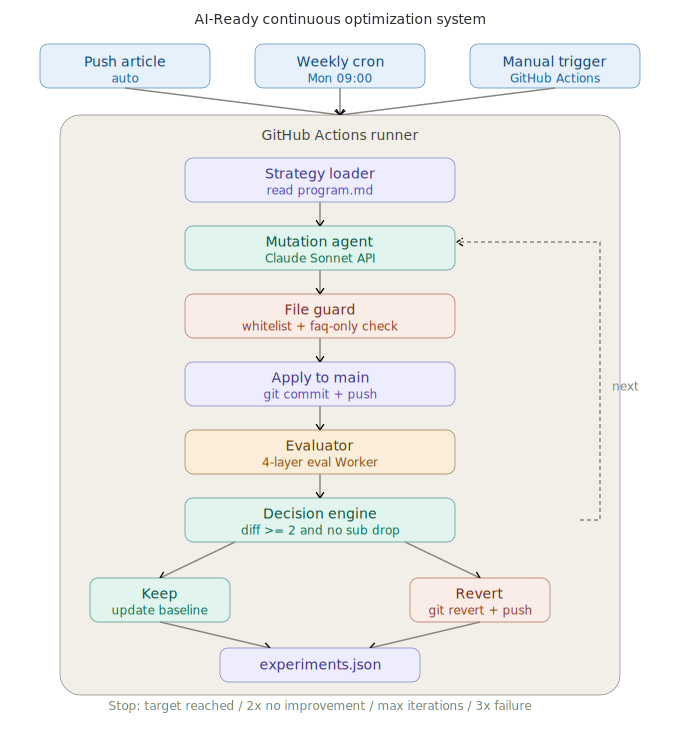
I built an AI-Ready Continuous Optimization System. The flow works like this: GitHub Actions trigger (push article / weekly Monday / manual) → mutation agent generates modifications based on strategy → file guard does whitelist checking → apply to production → eval Worker four-layer scoring → decision engine decides keep or revert → results written to experiments.json.
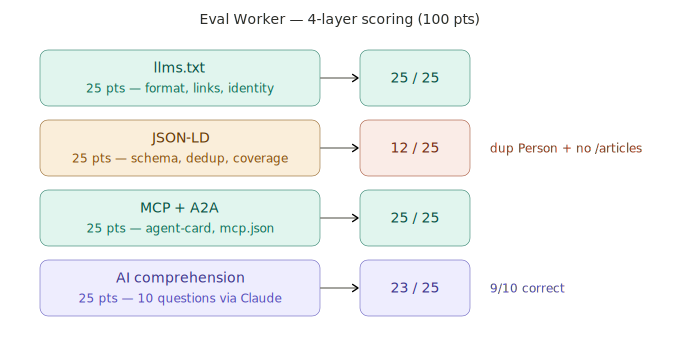
The four-layer scoring examines: llms.txt structure (can AI read your self-introduction?), JSON-LD completeness (is structured data correct?), MCP/A2A protocol support (have you opened the door for AI agents?), AI comprehension (after Claude reads your llms.txt, can it correctly answer questions about you?).
After the first round, scores went from 65 to 85. The system worked.
But then problems emerged.
Testing Yourself Doesn’t Count, No Matter How High the Score
After three e2e rounds, the agent chose to add FAQs to articles each time, eval showed no score change each time, and all three rounds were reverted. Looking at the reasons, I found the agent had no idea where the scores came from—because I hadn’t translated the eval scoring logic for it to see. It was like a student who doesn’t know the exam scope, only doing the questions it’s best at.
But the deeper problem wasn’t with the agent—it was with the entire loop itself.
I defined the metrics myself, let the agent optimize, then used the same eval to score it back. This is a closed loop. So what if scores went from 65 to 85 to 90? I can’t prove that “a 90-point website makes external AI truly understand me better.” System correctness doesn’t equal outcome correctness.
True sustainable optimization isn’t about making many changes, but about establishing a research system that can distinguish effective signals from meaningless fluctuations.
Having External AI Do the Testing
So I added a layer of external validation.
The approach: establish a 13-question benchmark (covering identity recognition, content understanding, cross-domain connections, timeliness, technical features, plus 3 anti-hallucination tests), using Perplexity as the external examiner. Perplexity searches the web before answering—it doesn’t read context I feed it, but finds information itself. If it can’t answer before optimization but can after, that’s meaningful ground truth.
I first ran 10 calibration rounds, measuring noise: same website, same question set, same model, asked 10 times consecutively. The score mean was 50.63, stddev 5.86. This means any score change smaller than ±11.72 could just be random fluctuation, not real improvement.
Then I set up GitHub Actions to automatically run a temporal baseline every day at 9 AM, with results auto-committed back to the repo. After five days, I had cross-day fluctuation data to distinguish between “Perplexity is in a good mood today so scores are high” and “website structure improved so scores are high.”
This entire system is designed to be fully automated. No need to monitor or push—data accumulates itself.
No Rush to Let New Metrics Drive Decisions
However, even with external validation, I didn’t want it to immediately determine keep or revert decisions.
Currently, Layer 5a (external AI cross-validation) is observe-only: it runs every round but doesn’t affect decisions, only records to the experiment log. My plan is to accumulate 20+ rounds, observe false positive and false negative rates, then decide whether to upgrade to soft gate (only prevents keep on strong negatives), then to full gate (external scores become formal decision criteria).
I’m just starting testing—can’t let new metrics change core decisions as soon as they’re plugged in. They must first be observed, calibrated, and proven.
Karpathy’s inspiration to me wasn’t just “AI can do research itself,” but: anyone with basic engineering ability can build a dedicated optimization loop for their own models, websites, or processes at relatively low cost. For researchers, it’s model training; for enterprises, it’s processes and knowledge bases; for me, this time’s starting point is turning my personal website into an experiment that can be continuously read, tested, compared, and optimized by AI.
paulkuo.tw is not just my personal website, but an experiment toward a more readable future self. Not just a showcase of what I’ve written, but a site where I co-construct knowledge with AI.
Thinking further ahead, will everyone’s digital avatar (“soul.md”) have such evolutionary frameworks in the future?
I don’t know. Continuing to explore.
Maybe I’m thinking wrong! That would be even better.
Actual System Architecture
Below is the complete flow and four-layer scoring reality of the AI-Ready Continuous Optimization System:
Here’s a summary of scope differences between my implementation and Karpathy’s autoresearch. Both share similar spirits but operate in different domains—they’re not the same type of system:
| Aspect | Karpathy autoresearch | My AI-Ready Continuous Optimization System |
|---|---|---|
| Primary Goal | Automate “model training research experiments,” finding better training configurations and architectures within fixed resources | Automate continuous optimization of “website and AI interface quality,” making websites easier for various AIs to correctly understand and cite |
| Domain & Target | Small language model training (e.g., nanochat / nanoGPT-type tasks) | Personal website paulkuo.tw structure, llms.txt, JSON-LD, agent protocols, etc. |
| Environment Type | Closed lab environment: single codebase, single dataset, single GPU, offline training experiments | Near-production: modifications directly affect website repo/production and accept external AI testing |
| Automation Unit | Code modifications to train.py, hyperparameter and training strategy experiments | Modifications to website content structure, metadata, llms.txt, FAQ sections, protocol settings, etc. |
| Pipeline Structure | Research loop: program.md → agent modifies train.py → run experiment → read validation metrics → decide keep or discard | Practical workflow: GitHub Actions trigger → mutation agent modify → file guard check → deploy → eval worker four-layer scoring → decision engine keep/revert → experiments.json |
| Evaluation Metric Nature | Single task internal metrics (e.g., validation loss), generated and used entirely within experimental environment | Multi-dimensional metrics: llms.txt structure, JSON-LD completeness, MCP/A2A support, AI comprehension, plus external Perplexity benchmark scores |
| External Validation | Almost no direct external world validation, focus on relative improvement and experimental efficiency | Additional Perplexity Q&A benchmark + multiple calibration, measuring noise, establishing temporal baseline, gradually evaluating whether changes truly improve external AI understanding |
| Rollback & Decision Strategy | Primarily validation set metrics, simpler design for not adopting worse configurations | Layered gates: internal four-layer eval drives keep/revert, external Layer 5a observe-only first, consider upgrading to soft gate or full gate after accumulating sufficient rounds |
| Subject Identity | ”AI helping AI do research”: LLM agent acts as junior researcher | ”AI helping humans maintain digital presence”: LLM agent helps me adjust personal website to make it more AI-readable |
| Typical User Threshold | Requires deep learning engineering background, GPU environment, and code manipulation skills | Requires DevOps/Web/GitHub Actions skills, but closer to actual content operations and personal branding |
Reference: Karpathy autoresearch GitHub

💬 Comments
Loading...