
看到 Andrej Karpathy 發表 autoresearch 時,腦裡閃過很多念頭。當 AI 可以開始做研究,人類在科研的位置該怎麼調整?AI 可以不斷優化跟你我的互動,提供更好的「傳道授業解惑」服務,我們要怎麼應對教育的衝擊?如果一個系統的目標、邊界、評估與回滾機制都設計得夠清楚,進化可以不必靠直覺與人為修改,而可以靠 AI 在明確邊界內進入持續優化迴圈,我們是否就更靠近「止於至善」的理想?
autoresearch 帶來的不只是方法論上的震撼,它把充滿人工作業、直覺判斷與零碎試誤的事情,收斂成了一個可持續循環、可被觀測、也可以被回滾的系統。給 AI 一個夠真實但規模可控的實驗場,讓它自己修改、自己跑、自己看結果,再決定哪些變更值得留下。
然後我就想自己動手測試。從一月起,幾乎每天都開新的專案,跟 AI 互動之後,決定用自己的網站做實驗。
如果 AI 是入口,網站就不只是陳列架
我們正進入一個轉折:愈來愈多的資訊交流、合作、搜尋、引用、甚至決策前的研究,都先經過 AI。不是搜尋引擎,是 AI。
Perplexity 回答問題的時候會引用來源,ChatGPT 的 browsing 模式會抓網站結構化資料,Claude 可以透過 llms.txt 理解網站。這代表什麼?代表一個網站的任務,正在從「被人看見」轉向「被 AI 正確理解」。SEO 優化的是搜尋引擎可見度;AEO(Answer Engine Optimization):也有人叫 GEO(Generative Engine Optimization):優化的是被 AI 正確摘要、正確引用、正確連結的能力,點擊率只是副產品。
若接受這個前提,那 paulkuo.tw 就不只是我的文章陳列架,而可以被設計成一個持續被人類測試、被 AI 理解、被 AI 優化的知識實體(knowledge entity),會是一個活的、進化的數位存在。
所以我就試著做看看。
把 autoresearch 的精神搬到網站上
Karpathy 的 autoresearch 目前專注在小型語言模型的訓練實驗上,我這裡是把「自動實驗迴圈」這個概念搬到網站優化領域。
我不是把 autoresearch 原封不動搬過來。模型訓練有 loss function,網站優化需要的是不同的東西。但精神是一樣的:定義目標、限縮邊界、建立評估、設計回滾,然後讓迴圈自己跑。
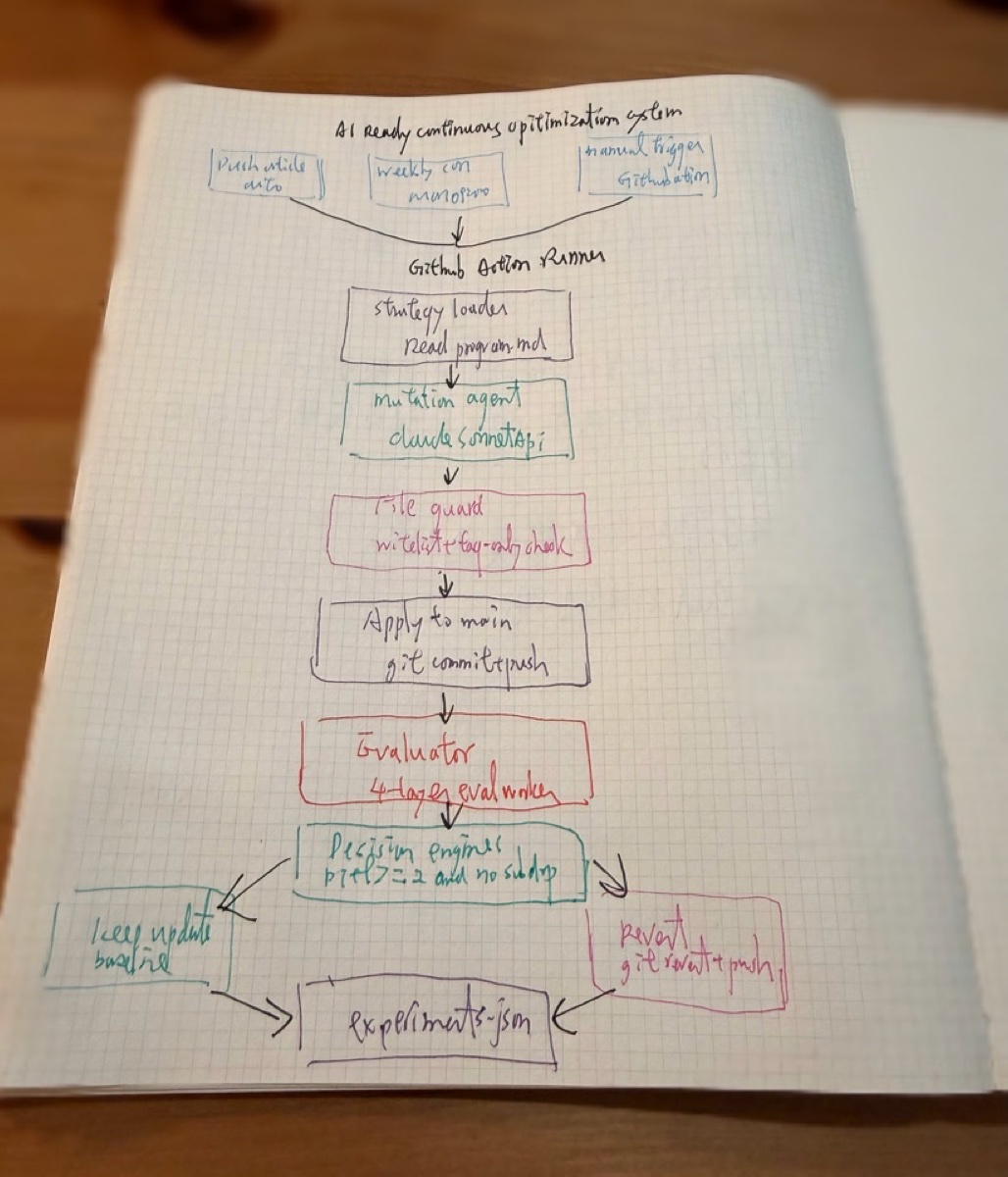
我建了一套 AI-Ready Continuous Optimization System。它的流程是這樣:GitHub Actions 觸發(push 文章 / 每週一 / 手動)→ mutation agent 根據策略產生修改 → file guard 做白名單檢查 → 套用到 production → eval Worker 四層評分 → decision engine 決定 keep 或 revert → 結果寫進 experiments.json。
四層評分分別看:llms.txt 結構(AI 讀得懂你的自我介紹嗎)、JSON-LD 完整性(結構化資料對不對)、MCP/A2A 協議支援(你有沒有為 AI agent 開門)、AI 理解度(Claude 讀完你的 llms.txt 之後,能正確回答關於你的問題嗎)。
第一輪跑完,分數從 65 拉到 85。系統跑通了。
但問題來了。
自己考自己,分數再高也不算數
三輪 e2e 跑下來,agent 每次都選擇幫文章加 FAQ,eval 每次都顯示分數不變,三輪全部 revert。我去看原因,發現 agent 根本不知道分數從哪裡丟的:因為我沒把 eval 的計分邏輯翻譯給它看。它就像一個不知道考試範圍的學生,只會做自己最會的題目。
但更深的問題不在 agent,在整個迴圈本身。
我自己定義指標、讓 agent 優化、再用同一套 eval 回頭打分。這是封閉迴圈。分數從 65 到 85 到 90 又如何?我沒辦法證明「90 分的網站,外部的 AI 真的更懂我」。system correctness 不等於 outcome correctness。
做很多修改可以讓分數一直上去,但那只是回饋迴圈在說謊。可持續的優化需要的是一套能區分有效訊號與無效波動的研究制度。
讓外部 AI 來考
所以我加了一層外部驗證。
做法是:建立 13 題 benchmark(涵蓋身份識別、內容理解、跨域連結、時效性、技術特色,還有 3 題反幻覺測試),用 Perplexity 當外部考官。Perplexity 會搜尋網路再回答,不是讀我餵的 context,而是自己去找。如果它優化前答不出來、優化後答得出來,那就是有意義的 ground truth。
先跑了 10 次 calibration,量測噪音:同一個網站、同一組題目、同一個模型,連續問 10 次,分數的 mean 是 50.63,stddev 是 5.86。這代表任何小於 ±11.72 的分數變化,都可能只是隨機波動,不算真正的改善。
然後設了 GitHub Actions,每天早上 9 點自動跑一次 temporal baseline,結果自動 commit 回 repo。五天之後,我就有跨天的波動數據,可以區分「Perplexity 今天心情好所以分數高」和「網站結構改善所以分數高」。
這整套系統設計成全自動。不用去盯去催,資料自己累積。
不急著讓新指標主導決策
不過,即使有了外部驗證,我也不想一開始就讓它決定 keep 或 revert。
目前 Layer 5a(外部 AI 交叉驗證)是 observe-only:每輪都跑,但不影響決策,只記錄到 experiment log。我的規劃是累積 20 輪以上,觀察 false positive 和 false negative 的比率,之後才決定要不要升級成 soft gate(只在強烈負向時阻止 keep),再到 full gate(外部分數成為正式決策條件)。
才剛開始做測試,不能讓新指標一接進來就改變核心決策。它必須先被觀察、被校準、被證明。
Karpathy 給我的啟發,不只是「AI 可以自己做研究」,而是:只要有基本工程能力,每個人都可以用相對低成本,為自己的模型、網站或流程,建立一個專屬的 optimization loop。對研究者來說是模型訓練,對企業來說是流程與知識庫,對我來說,這次的起點是把我的個人網站變成一個可以被 AI 持續讀取、測試、比較與優化的實驗。
paulkuo.tw 是我跟 AI 共構知識的現場:文章、代碼和這套優化迴圈,都是那個現場的一部分。
想更遠一點,未來,每個人的數位分身(「soul.md」)都會有這樣的演化框架嗎?
不知道。繼續探尋。
也許我想錯了!那更棒。
系統實際架構
以下是 AI-Ready Continuous Optimization System 的完整流程與四層評分實況:
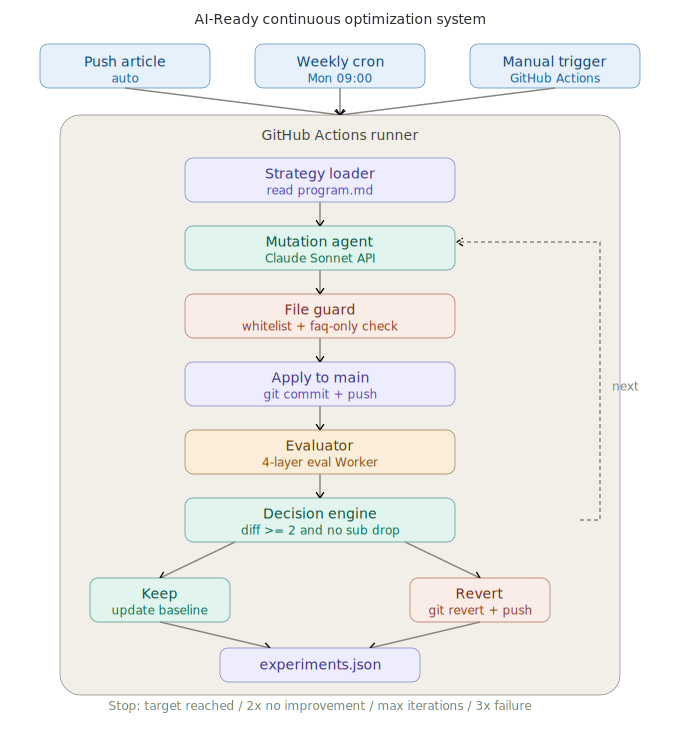
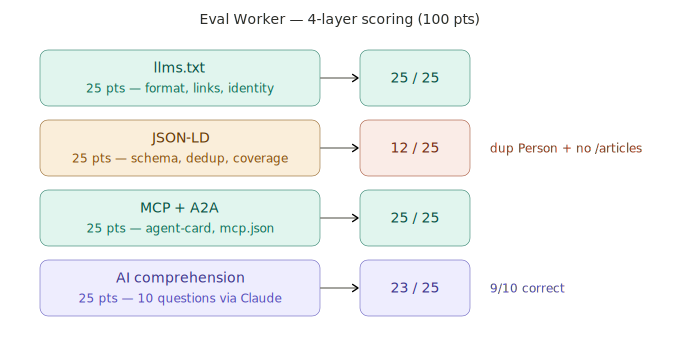
下面整理我這次實作與 Karpathy autoresearch 的範圍差異,兩者精神相近但領域不同,不是同一種系統:
| 面向 | Karpathy autoresearch | 我的 AI-Ready Continuous Optimization System |
|---|---|---|
| 主要目標 | 自動化「模型訓練研究實驗」,在固定資源內找到更好的訓練設定與架構 | 自動化「網站與 AI 介面品質」的持續優化,讓網站更容易被各家 AI 正確理解與引用 |
| 領域與對象 | 小型語言模型訓練(例如 nanochat / nanoGPT 類任務) | 個人網站 paulkuo.tw 的結構、llms.txt、JSON-LD、agent 協議等 |
| 環境型態 | 封閉實驗室環境:單一 codebase、單一資料集、單 GPU,離線訓練實驗 | 接近 production:修改直接作用在網站 repo / production,並接受外部 AI 的實測 |
| 自動化單位 | 針對 train.py 的程式碼修改、超參數與訓練策略實驗 | 針對網站內容結構、metadata、llms.txt、FAQ 區塊、協議設定等進行修改 |
| Pipeline 結構 | 研究 loop:program.md → agent 改 train.py → 跑實驗 → 讀驗證指標 → 決定保留或丟棄 | 實務 workflow:GitHub Actions 觸發 → mutation agent 修改 → file guard 檢查 → 部署 → eval worker 四層評分 → decision engine keep/revert → experiments.json |
| 評估指標性質 | 單一任務內部指標(例如 validation loss),完全在實驗環境內產生與使用 | 多維指標:llms.txt 結構、JSON-LD 完整度、MCP/A2A 支援、AI 理解度,再加外部 Perplexity benchmark 分數 |
| 外部驗證 | 幾乎沒有直接外部世界驗證,重點是相對改進和實驗效率 | 額外設計 Perplexity 問答 benchmark + 多次 calibration,測量噪音、建立 temporal baseline,逐步評估改動是否真的提升外部 AI 的理解 |
| 回滾與決策策略 | 以驗證集指標為主,較差設定不採用,設計較簡單 | 分層 gate:內部四層 eval 主導 keep/revert,外部 Layer 5a 先 observe-only,累積足夠輪數後才考慮升級為 soft gate 或 full gate |
| 對象身分 | 「AI 幫 AI 做研究」:LLM agent 充當 junior researcher | 「AI 幫人維護數位存在」:LLM agent 幫我調整個人網站,讓它對 AI 更可讀 |
| 典型使用者門檻 | 需要深度學習工程背景、GPU 環境與程式碼操作能力 | 需要 DevOps / Web / GitHub Actions 能力,但更貼近實際內容營運與個人品牌 |

💬 留言討論
載入中...