
在 Facebook 滑到Lucy的貼文,她分享一套開源專案投資評分卡(Lucy Chen,新加坡 Zoo Capital 的 EIR,管理規模超過 20 億美金的基金)。
Lucy分享的框架很清楚:五個維度、加權計分、一票否決機制。很多開發者一直引以為傲的技術,在真實商業落地中還有很多坑。
Lucy 的框架來自實戰——她在 NVIDIA GTC 之前就用這套評分卡標記了 LMCache 這個項目,給出 7.78 分的「黑馬」評級,兩週後 NVIDIA 發布 Dynamo 1.0 就把 LMCache 收編進官方集成名單。她設計的投資評分卡能抓到訊號。
但我也有另一個念頭:這把尺是否能普惠尋常大眾?
換個角度
Lucy Chen 的框架是從 VC 投資角度出發的。考慮出場路徑、團隊國際化、社群治理、資本效率。這些對投資人來說都是關鍵的問題。
但對許多靠AI獨立做工具的個人來說,如果我壓根沒有想被投資?如果我只是想做開心?如果我沒有要商轉?如果這時代已經不適合販售軟體小工具?
例如,我做了即時會議翻譯工具、多模型辯論引擎等,都是我一個人加上 Claude 從零做起的。我沒有被投資的需要,不需要有退出路徑,但我需要有”人”告訴我:做的這個東西的價值與調整方向。
這個問題在 Lucy Chen 的框架裡被隱含在其他維度裡。我想獨立出來。
三個改動
我做了三件事。
第一,拿掉「團隊能力」維度。團隊是公司的重要組成。但我想針對服務評估,日後一個人可能做十個產品,這個維度可能就沒有鑑別力。我把它抽離成一個不計分的「Builder Profile」前置欄位——留給AI參考,不影響總分。
第二,新增「問題解決力」維度。你解決的問題是你自己假想的,還是真的有五個以上的人獨立描述過這個痛點?現有替代方案是什麼?你的解法比現有方案好多少——是 10 倍還是略好?這些問題應該是任何 builder 在動手之前第一個被問的。
第三,商業化維度做了階段適配。一個還在概念期的 side project 被問「月經常性收入多少」是不公平的,但被問「你有沒有想過怎麼賺錢」、「推薦到市場」是合理的。我讓使用者先選產品階段——概念期、已上線、有用戶、有收入——不同階段會看到完全不同的評估訊號。
改完之後,五個維度變成:問題解決力(25%)、市場驗證(20%)、技術護城河(20%)、商業化路徑(20%)、長線可持續性(15%)。每個維度下面有 4-6 個訊號,每個訊號打 0-10 分,加權算出總分。
5.01 分——被自己的尺打臉
框架設計完,我用自己的即時翻譯工具跑了一次完整評估。
結果:5.01 / 10。紅燈。
分數分佈是非常典型的工程師產品輪廓:問題解決力 7.0 分,技術護城河 6.2 分(三引擎 STT 路由、獨家語料累積),長線可持續性 5.5 分,但市場驗證 4.0 分(沒有外部用戶回訪數據),商業化 2.0 分(幾乎沒有收費計畫)。
雷達圖的形狀嚴重偏科——問題解決力和技術那兩角撐出去,市場和商業化那兩角幾乎貼在地板。
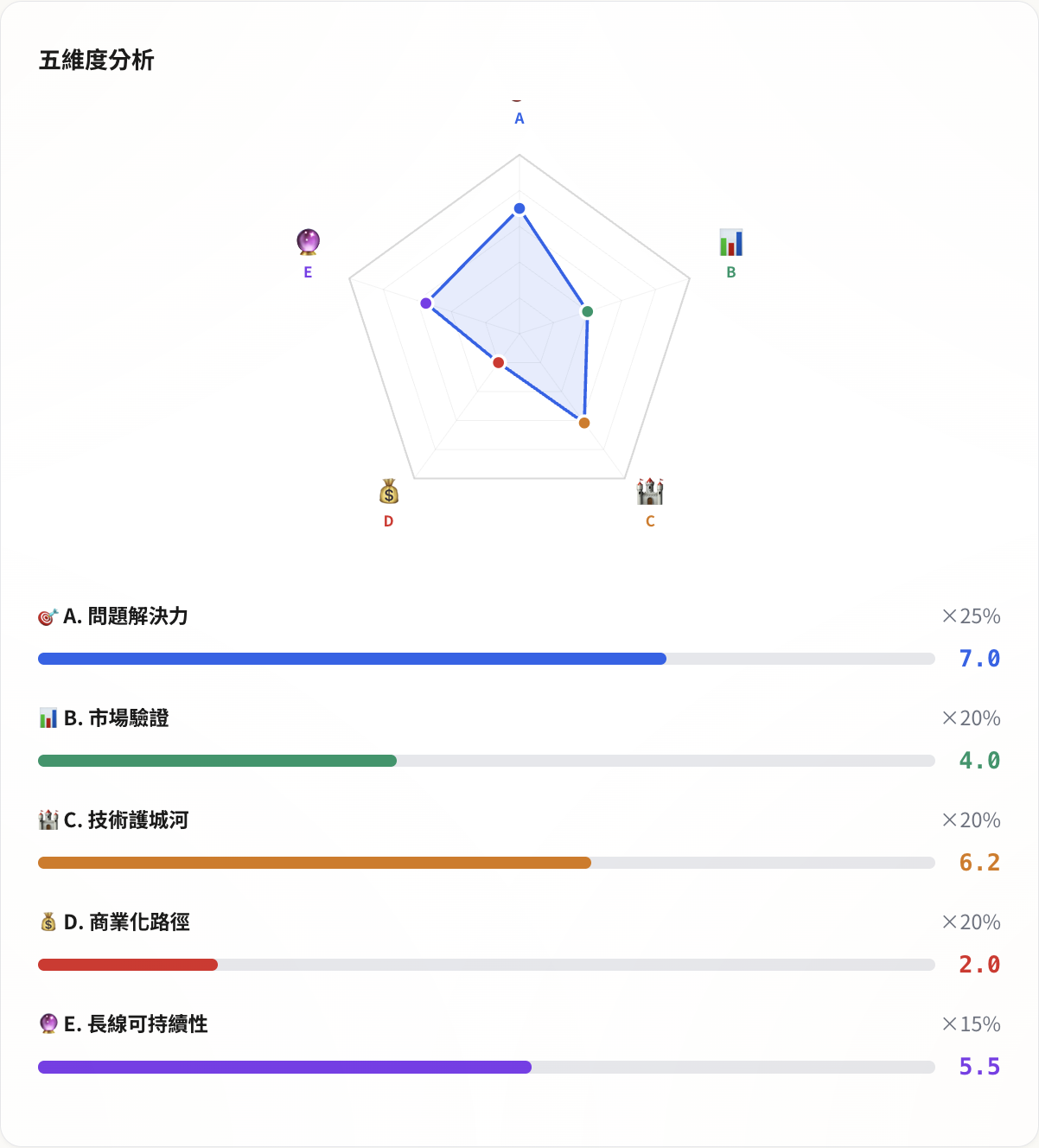
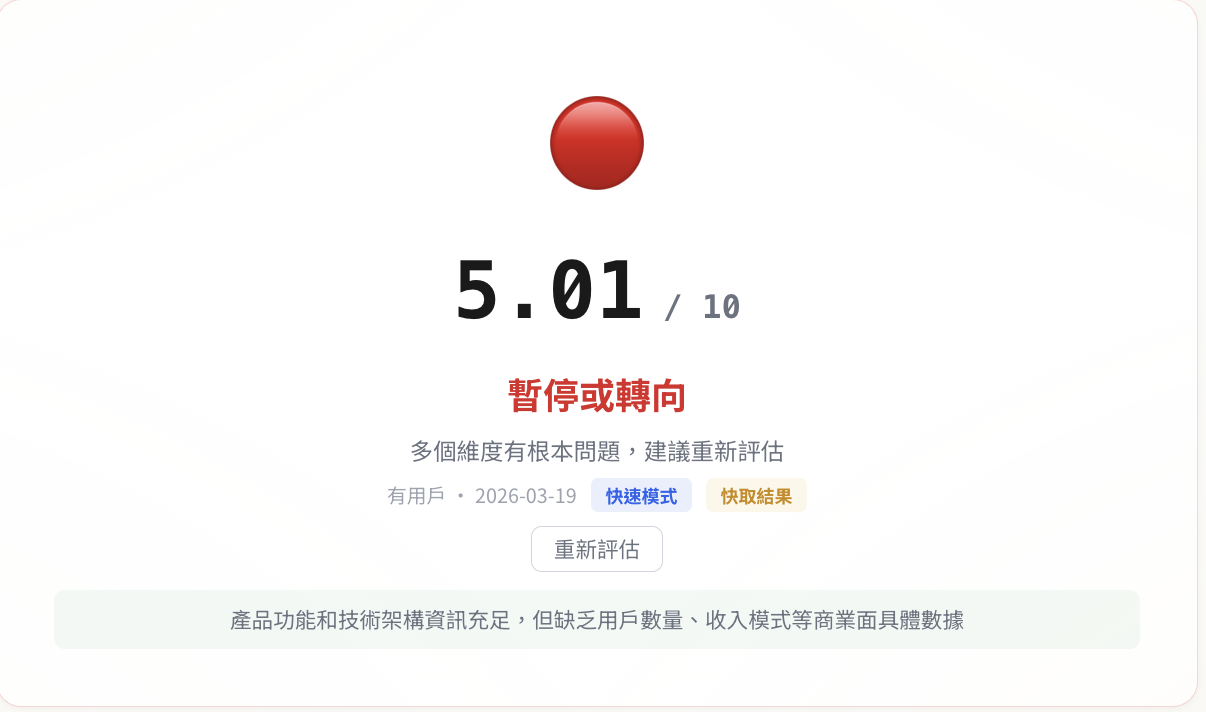
這個結果正確(雖然看起來有點刺眼),分數低是因為它說出事實:技術好了不等於產品做好。我花時間在 Qwen3-ASR 和 Deepgram 的路由邏輯上,但還沒特別想過「誰會為這個付錢」。因為我在這個階段確實沒有收費的打算。
所以,這把尺誠實,沒有幻覺。
先看市場再動手
依照慣例,在動手寫code前先做市場偵察。
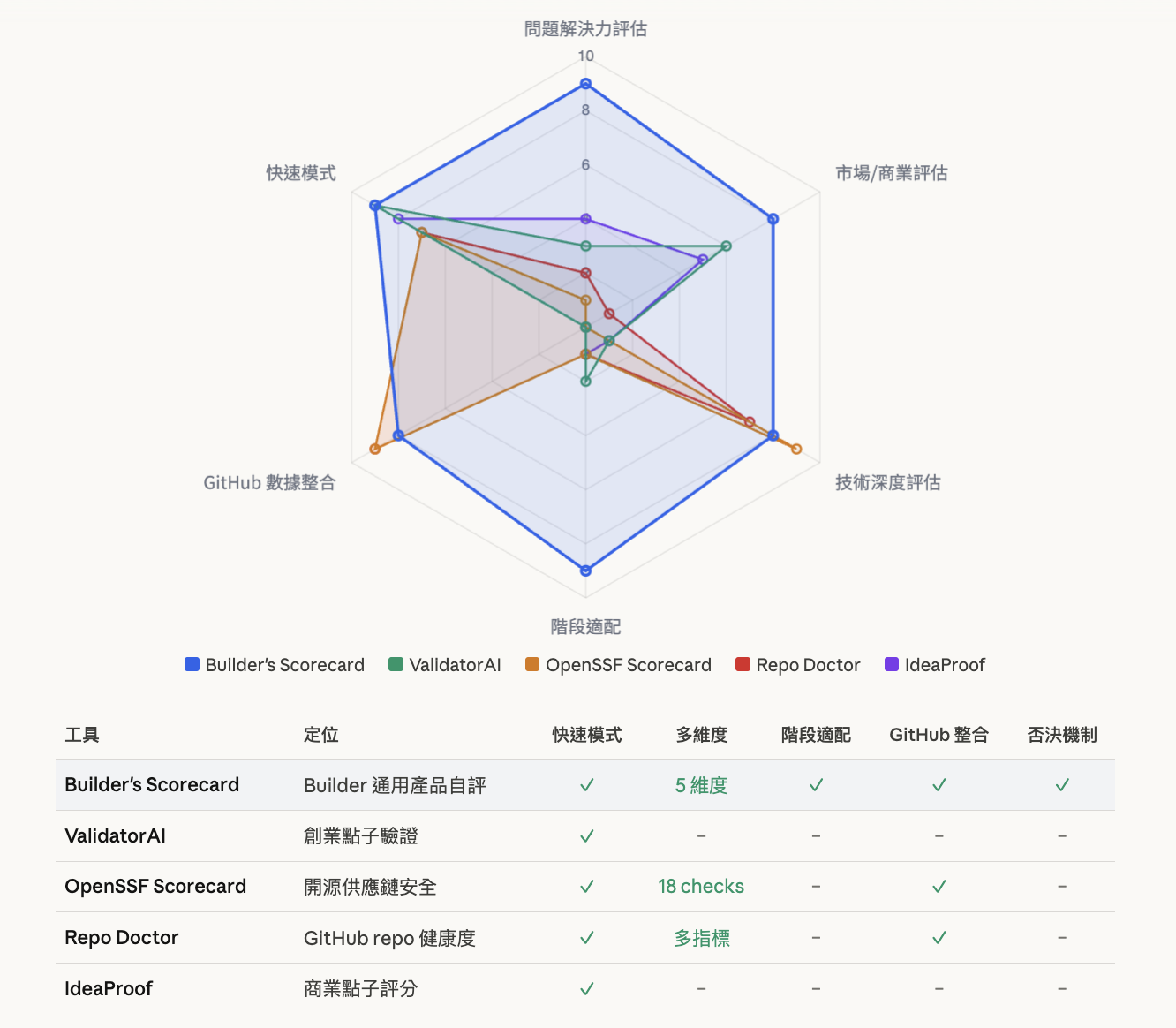
找到一些類似服務,例如 ValidatorAI 讓你貼一句話就能驗證創業點子,累積超過 30 萬次使用。OpenSSF Scorecard 專門評估開源專案的供應鏈安全。Repo Doctor 用 GitHub API 自動抓結構化數據做健康度分析。
每一個都有值得學的地方:ValidatorAI 的「30 秒出結果」降低了使用門檻,這直接啟發了快速模式的設計;OpenSSF 的分數解讀機制提醒我——低分不代表「不好」,要幫使用者正確解讀;Repo Doctor 的 GitHub 結構化數據擷取讓 AI 可以專注在需要判斷力的部分。
但沒有一個現成的工具完成我想做的事(也許我的調查不夠):用一套框架,從五個維度同時評估一個產品,不管它是開源工具、SaaS、還是內部系統都適用。
確認了市場定位後,我開始寫 code。
一天,五個階段
從看到貼文到起心動念去執行,是一天。整個開發用 AI 協作完成——Chat session 做偵察和規劃,Code session 寫程式碼,Cowork session 處理批次作業和狀態管理。
Phase 1 做核心框架:五維度 × 30 個訊號的前端介面、SVG 雷達圖、快速模式和完整模式、中英雙語切換、Markdown 和 JSON 匯出。純前端,不碰 API。
Phase 2 接入 AI:用 Claude API 做兩件事——Prompt A 負責根據使用者貼的產品描述自動為 30 個訊號打分(temperature = 0,確保同一個產品跑多次分數穩定),Prompt B 負責根據評估結果生成策略建議(temperature = 0.3,允許建議有變化)。
Phase 3 擴充輸入源:支援四種輸入——純文字描述、GitHub URL(自動抓 stars / contributors / forks / license 等結構化數據再送 AI 評估)、README 檔案上傳、一般網站 URL 擷取。
Phase 4 做防護和社交:四層防禦架構(Rate Limit、Auth Gate、Result Cache、Daily Cost Cap)確保開放後不會被濫用。加上儲存功能、動態牆、分享連結,讓評估結果可以被發現和討論。
Phase 5 收尾打磨:首頁加入口卡片、方法論介紹頁、SEO 強化(JSON-LD + FAQ Schema)、llms.txt 更新。
每個 Phase 之間不跳步——Phase 2 的 AI prompt 格式要對齊 Phase 1 的資料結構,Phase 3 的 GitHub 數據要餵進 Phase 2 的 prompt。先偵察再動手,先規劃再執行。
尺規的鑑別力
工具上線後做測試:拿三個完全不同的產品跑評估。
LangChain:8.02 分。13 萬 stars、3,659 contributors、有 LangSmith 付費產品。五個維度都在 7 分以上,只有長線可持續性因為大廠威脅稍低。
Lucy Chen 的 OSS Investment Scorecard 本身:6.82 分。框架設計扎實、問題真實,測試時 233 stars、2 個 contributor、零收入模式。
我的即時翻譯工具:5.01 分。技術面有底子,市場面和商業化是空白。
三個產品,三種完全不同的雷達圖形狀。分數有區分度,而且區分的方向符合觀察。這把尺應該有一定的鑑別力。
重要的不是分數
在 2026 年,一個人加上 AI,確實可以在幾天內,把一個想法從概念推進成真正上線的工具。能快速上線,不代表上線的東西值得被做出來。
在後 AI 社會裡,打造工具的門檻正在快速降低。越來越多人都可能成為 builder,創造工具也不再只是少數技術者的專利。問題也從這裡浮出水面:我們做出來的工具,真的適合人使用嗎?真的有解決問題嗎?
當一個念頭剛開始浮現時,或當產品做到一半時,我們是否有能力一邊前進,一邊停下來檢查:這是不是一個值得被做出來的東西?它服務的是人的需求,還是只是滿足了我們「能做出來」的衝動?
Builder’s Scorecard 不是要給”正確答案”。它把五個維度的數據擺在你面前,讓你自己判斷。
重要的不只有總分,還有雷達圖的形狀。一個 6.0 分但五角均勻的產品,比一個 7.0 分但某個維度是 1 的產品可能更健康。但,也可能是你刻意為之。在創造的路上,一切都是美好的。姿勢醜沒關係,繼續前進就好。
如果你也做了什麼工具或 side project,來量一下。不是為了分數,是為了看見自己的盲區。

💬 留言討論
載入中...