TL;DR — 4/29 GitHub 無預警停權,沒有理由也沒回信。兩週重建出五層韌性架構:本地優先 × 三點 SSoT × 繞過 CI 直推 × 契約測試與混沌演練 × 跨 session AI 協同。核心教訓是:不能讓任何一家服務變成必經之路。這個原則不只適用於內部系統,也適用於你所依賴的外部服務。
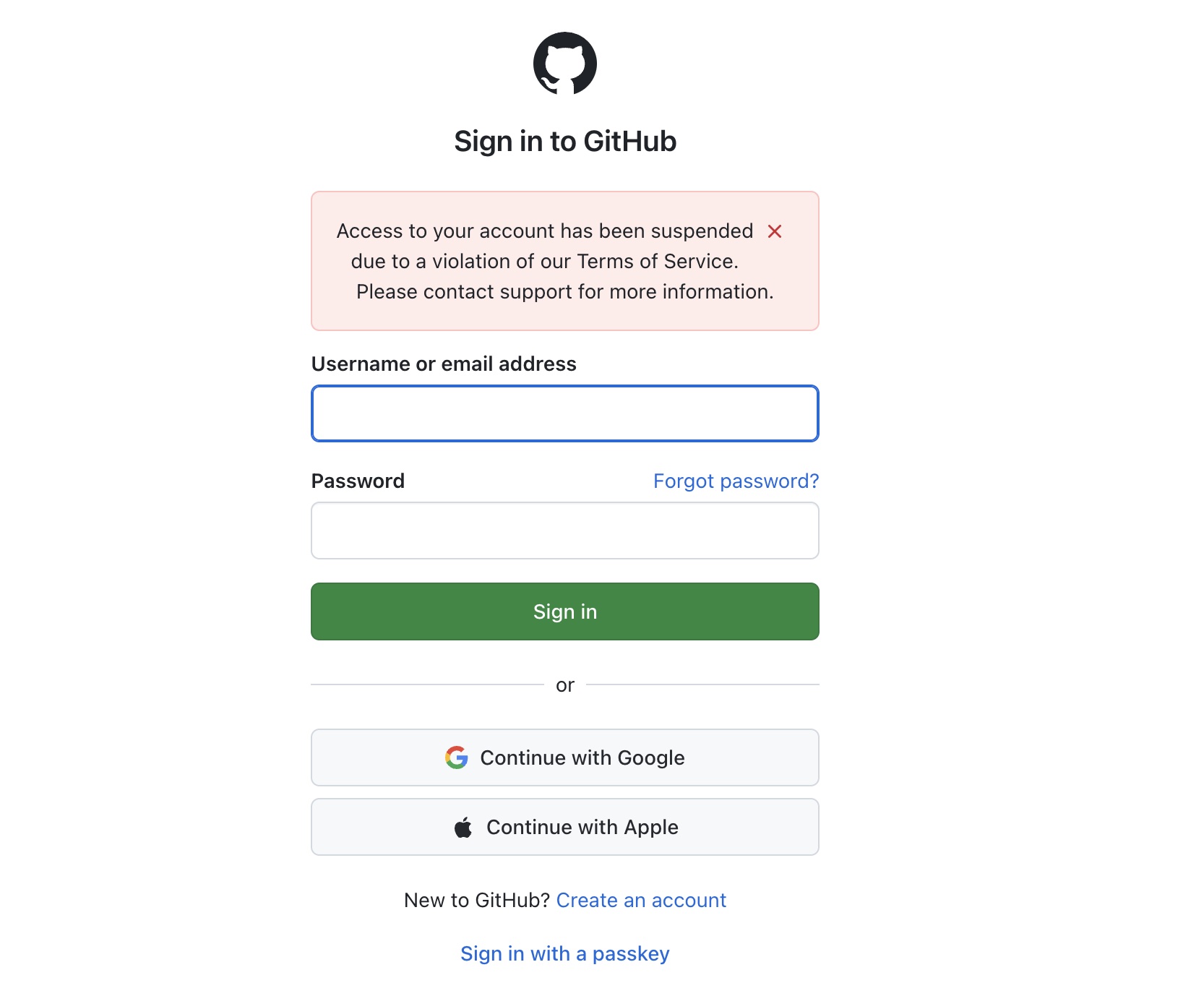
2026 年 4 月 29 日,我準備推 commit 到 paulkuo.tw 的 repo,一直出現錯誤訊息。後來上網看 GitHub,發現完全點不進 GitHub 帳號(如圖)。我一度以為只是暫時性的無法登入,過幾小時就好。但,並沒有(如截圖)。
Access to your account has been suspended due to a violation of our Terms of Service. Please contact support for more information.
對 support 發了申訴信,到今天還沒收到任何回覆。
那時我才意識到,我把整個程式碼管理、CI、部署、甚至我的工作流核心,全部綁在一家公司身上有風險。這家公司剛剛把我閹了,不用給我理由。
為什麼一家服務被停權,等於整個工作流被停權?
如果拆解我那天的工作鏈,會發現它是一條五個節點的單線:
寫作 → GitHub 主倉庫 → GitHub Actions(CI)→ Cloudflare Pages(部署)→ paulkuo.tw 上線
中間三個節點全部依賴 GitHub。其中 GitHub Actions 是觸發 Cloudflare Pages 自動部署的關鍵。也就是說,我連 paulkuo.tw 都發不了文,因為部署這件事根本不在我自己的機器上跑。
更糟的是,這條鏈我以前從來沒想過要拆解。它「就是這樣運作」,工程師圈這樣設計是預設值。當 GitHub 還活著的時候,整條流暢得讓人忘了它有單點失效(single point of failure)的本質。
直到 4/29,這個本質暴露出來。
三哩島事故告訴我們什麼?
1979 年 3 月 28 日凌晨,美國賓州三哩島核電廠發生美國史上最嚴重的民用核電事故。起因是次級系統的主給水泵停止運作,主系統壓力急速上升。本應自動關閉的洩壓閥(PORV)卻卡住未關,導致冷卻水持續流失。
但儀表顯示誤導了控制室:洩壓閥的指示燈只顯示「指令已發送」而非「閥門已關」,操作員誤以為閥已關閉。看到加壓器水位上升,以為冷卻水過多,反而關閉了高壓注水系統。結果冷卻水從卡住的閥持續流失,爐心逐漸過熱、部分熔毀。
事故並非單一錯誤造成,而是三個小問題同時累積,現場人員不可能在一分鐘不到內做出準確的回應。
這起事件後來成為 Charles Perrow 「正常事故」(Normal Accidents)理論的開山案例。Perrow 本人就是 TMI 事故調查員之一,1984 年出版的《Normal Accidents》前半部就是他對這場事故的逐步重建。Perrow 提出兩個核心概念:「緊密耦合」(一個環節出事會快速傳染到下個環節)與「複雜性互動」(不同子系統會在意想不到的方式互相影響)。在這種系統裡,小錯誤會被快速放大成大災難。這不是有沒有出錯的問題,是「遲早會出錯」的問題。
真正該被檢討的不是某個操作員的失誤,而是整個系統的設計與管理方式。
我們需要的不是安全意識,是安全系統。
把系統搞好,有緩衝區,有餘裕,有穩定的迴路,我們才能有恃無恐。
這個道理不只適用於我們自己內部的系統,也適用於我們所依賴的外部系統。 當你把整條工作命脈託付給一家供應商,那家供應商本身就是你系統的一部分。它的脆弱,就是你的脆弱。
GitHub 的停權對我來說,就是我自己的三哩島。
兩週重建:paulkuo.tw 的五層韌性架構
從 4/29 起我就決定不能只依賴 GitHub,我規劃並建置「透過 AI 執行工程」所需要的韌性系統,持續演化,到 5/12 才驗收上線貼文的功能。架構分五層,每一層都針對「不能讓任何一家服務變成必經之路」這個原則做了解耦。
完整鳥瞰如下:
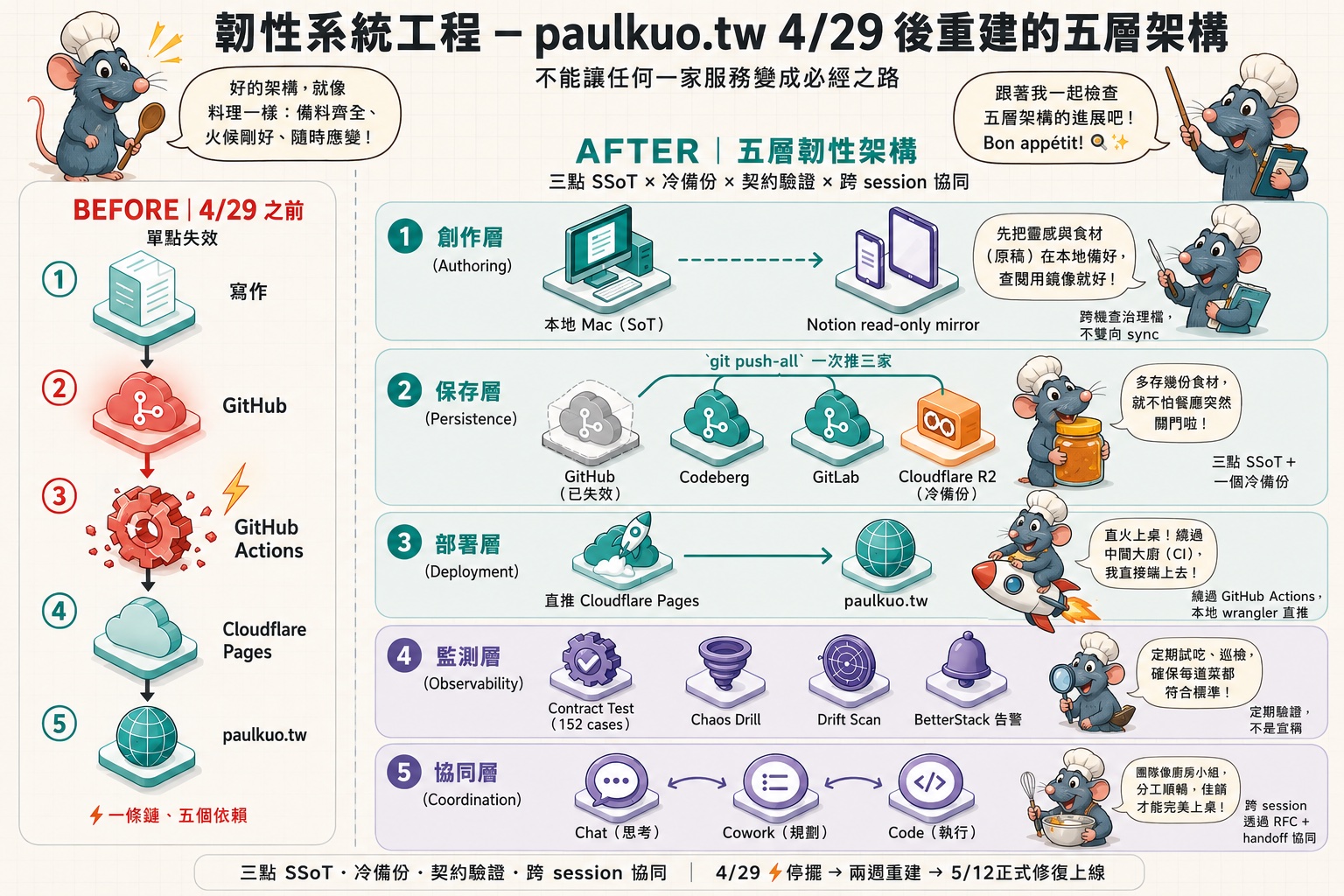
① 創作層(Authoring)
本地 Mac 是真正的原稿(source of truth),Notion 只是一個讓我手機、iPad、跨機器能查治理檔的唯讀 mirror,不雙向 sync。
這個邏輯很重要:以前我覺得「Notion 在雲端、跨機器同步、有版本歷史,自然是 SoT」。但這假設了 Notion 永遠活著。事件後我反過來想:真正的原稿應該在我能完全掌控的地方,也就是本地 Mac。Notion 退一步當顯示層,壞了也不會卡死我。
② 保存層(Persistence)
三點 SSoT + 一個冷備份:
- Codeberg(歐洲開源 Git host)
- GitLab(商業 Git host)
- 本地 Mac(master copy)
- Cloudflare R2(離線冷備份,存 repo bundle 與 memory snapshot)
我設了一個 git push-all alias,一個指令同時推三家。GitHub origin 留在 remote 清單裡,但每次 push 都會 fail。我刻意保留它作為「事件起點的紀念碑」,提醒自己這個架構是怎麼來的。等日後恢復,我一樣會使用它。
R2 是 Git host 之外的第四份保險。萬一三家 Git host 同時出事(極不可能但理論上會),bundle 還在 Cloudflare 物件儲存裡。
③ 部署層(Deployment)
用 wrangler 從本地直推 Cloudflare Pages,繞過 GitHub Actions。整條部署管線跟 GitHub 的存活完全脫鉤。
這是工程上最容易被忽略的環節。很多人重建 Git 備援的時候,忘了 CI 也是 GitHub。部署管線的解耦比 Git 鏡像更關鍵,因為 Git 你可以慢慢補,部署斷了你連發布都做不到。
④ 監測層(Observability)
韌性需要定期驗證:
- 契約測試 152 個 endpoint:每天 LaunchAgent 自動跑一次,比對實際 API 行為與規格定義有沒有漂移
- 混沌演練(chaos drill):H1 演練每週跑一次,故意破壞一個關鍵節點,看系統能不能自動恢復
- 漂移掃描(drift scan):自動偵測有沒有 endpoint 偷偷被新增或修改卻沒寫進規格
- BetterStack 告警:契約測試失敗會推到 BetterStack,再 email 以及 SMS 通知我
這層是這套系統最容易被輕視的部分。沒這層,前三層的「韌性」是宣稱出來的;有這層,韌性是每天被驗證的。
⑤ 協同層(Coordination)
這層處理的不是基礎設施,是人與 AI 的協作方式。
我用三種 AI session 形成分工:
- Chat(思考):問題拆解、找方向、討論架構
- Cowork(規劃):整理文件、規劃任務、產出工單
- Code(執行):把規劃轉成程式碼、實作功能、跑測試
三者之間靠 RFC 機制 + handoff 文件 + 共享待辦佇列(PENDING.md)協同。我設計了 session-handoff skill 當作這套協作的紀律:每次 session 結束都要按格式寫 handoff,下次 session 開場讀 handoff 接手。
這套韌性架構不是下指令讓 AI 幫我做出來。它是花了兩週時間,在我的踩坑痛苦上,跟三種 session 反覆磨合、再踩坑、修正流程才慢慢定型,而且還在修改。
為什麼「一週建好 AI 員工系統」對我不適用?
兩週重建的過程裡,我有一個強烈的感受:
市面上那些「一週建好 AI 員工系統」的課程或現成 Skills 包,對別人可能行,對我不行。
我用一個比喻:每一個 Skill 像是一種蛋白質。蛋白質要折疊成什麼形狀、發揮什麼功能,取決於它所處的細胞環境、酸鹼度、其他蛋白質的互動。蛋白質要折成不同的形狀,做出不同的事。
Skills 也一樣。同一組「寫作 skill」「部署 skill」「客服 skill」,丟到不同企業、不同個體手上,會折出完全不同的形狀。因為任務邊界與企業需求一定有相異之處。個人與企業的目標可能相似,但工作流的縫隙、資料的脈絡、決策的優先序,全都不一樣。
所以 AI Agent 系統設計,會需要花大量時間去優化管線與內部參數。不是用了某個 framework 就好,是要在你自己的工作場景裡反覆迭代。
我天天修改,才用兩週跑完。我開發過軟體,管理過軟體工程團隊,也開始累積一些 AI 協作的經驗。對沒有這些背景的人,或許會永遠卡住。當然,也可能更快。但不太可能是給一個提示詞,一切都自動完成。
兩週重建,我學到的五件事
一、韌性系統的設計,不是讓系統強到不會壞,而是允許局部壞掉、且能夠補位。
Nassim Taleb 在《反脆弱》裡提出三分法:脆弱(fragile,受到壓力會壞)、強韌(robust,受到壓力不壞)、反脆弱(antifragile,受到壓力反而變強)。傳統工程追求「強韌」,也就是強到不會壞。但複雜世界裡,「強韌」是一種幻覺,因為你永遠不知道下一個壓力從哪來。真正該追求的是韌性:壞了不會拖垮整體,壞了還能修。
我那條五節點的單線就是「假強韌」:它運作很順、看起來很穩,但只能撐到第一次衝擊。
二、Agent 的能力強大,但「丟一句指令、剩下交給 AI」這種劇本目前還不存在。
兩週裡我跟 AI 來來回回協作了至少幾百輪。AI 的執行力遠超人類,但收斂能力(把多個分歧的 AI 建議收斂成一個可執行決策)目前還是斷層。每一輪都需要人接手做這件事。
三、所以個體建置 AI 員工系統,沒有速成的快餐。
承上。Skills 像蛋白質,折疊形狀取決於你的細胞環境。別人的折法你拿來不一定能用。你的工作流、你的審美、你的決策模式,最後會塑造出一套只有你能用的系統。這也是為什麼這篇文章的架構,公開出來大家可以參考,但你照抄不一定有效。
四、韌性系統需要 Human in the Loop:設計階段與執行階段都不能少。
第二件講的是 AI 現在的能力限制。這條講的是設計選擇:就算哪天 AI 能力夠了,韌性系統的設計裡,人類仍應該佔有關鍵節點。
HITL(human in the loop)的角色分兩個階段:
設計階段:架構決策、依賴邊界、降級策略、什麼可以壞、什麼絕對不能壞,這些都是人類要拍的判斷。AI 能列選項、能展開 trade-off,但收斂到一個決策、為後果負責的還是人。
執行階段:契約測試的結果要不要當「真實的問題」、混沌演練暴露的 bug 要不要立刻修、漂移掃描跳出來的 endpoint 是「合法演進」還是「規格漏洞」,每一筆都需要人類介入判斷。系統能恢復到什麼程度,最後看人有沒有在場。
韌性系統不是「全自動」的系統。 它是設計階段有意識讓人類處於關鍵節點、執行階段持續被人類監督的系統。如果把整套丟給 AI 跑、自己不上線,韌性最多只是宣稱出來的。直到第一次出事,AI 給你 5 個可能的根因,但沒有一個能拍板,你才發現問題從來不在 AI 不夠強,是沒人在場。
五、AI 加速了軟體工程的「體力活」,但同時放大了另一種需求:需要人類細膩判斷的「決策密度」。
寫程式的時間變短了,但要決定寫什麼、為什麼這樣寫、什麼時候不寫、如何把多個 AI 的建議收斂成一個方案,這些決策密度變高了。一個小時的工作可能濃縮了 30 個微決策,每個都需要判斷力。
我一時想不到好名字,姑且叫它「判斷力經濟」。
判斷力經濟正在崛起
過去十年,市場補貼的是「執行力」:會寫程式、會做設計、會跑數據的人薪水水漲船高。
未來十年,市場可能補貼的是「判斷力」。因為執行這件事,AI 已經能幫你做到一個水準了。
我看過一個說法:知識工作者的角色,正在從「Maker(執行者)」過渡到「Curator(策展人)」、最後落腳在「Judge(裁判官)」。三個位置對應三種不同的稀缺性。做得出來,越來越不稀缺;做得到位、做得有品味,還算稀缺;判斷該不該做、何時停下、為後果負責,最稀缺。
4/29 GitHub 把我斷線,我以為我失去的是某一種網路功能。仔細想了一下,發現,我是把架構決策權放棄了:這套系統長什麼樣、依賴誰、不依賴誰、怎麼驗證、怎麼修,這些決策從來都該是我的,只是以前我把它默認外包了。
兩週後 5/12 文章可以開始上傳,我沒有特別感動。倒是想到一句話:不該把命脈託付給一家公司或者重壓在某個系統、然後還聲稱自己是自由的。

💬 留言討論
載入中...