TL;DR: On 4/29, GitHub suspended my account without warning—no reason, no response. Two weeks rebuilding a five-layer resilience architecture: local-first × triple SSoT × bypass CI direct push × contract testing and chaos engineering × cross-session AI collaboration. Core lesson: Can’t let any single service become a chokepoint. This principle applies not just to internal systems, but also to external services you depend on.
On April 29, 2026, I was trying to push a commit to the paulkuo.tw repo when I kept getting error messages. Later when I checked GitHub online, I found I couldn’t access my GitHub account at all (as shown). I initially thought it was just temporary login issues that would resolve in a few hours. But it didn’t (as screenshot shows).
Access to your account has been suspended due to a violation of our Terms of Service. Please contact support for more information.
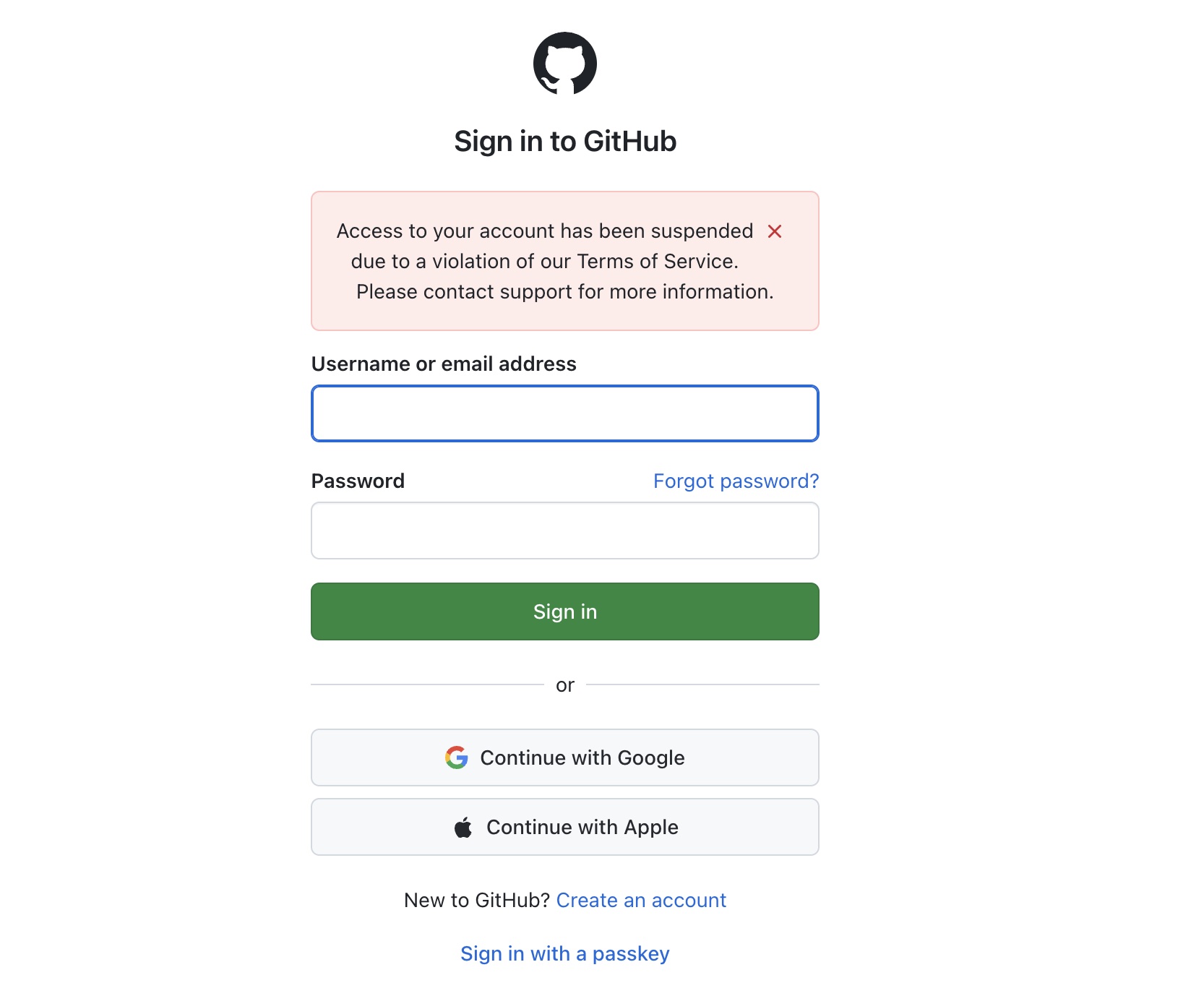
I sent an appeal to support, and still haven’t received any response to this day.
That’s when I realized the risk of tying my entire code management, CI, deployment, and even my core workflow to a single company. This company just cut me off, without needing to give me a reason.
Why Does One Service Suspension Equal Total Workflow Shutdown?
If I break down my workflow chain that day, it was a five-node single line:
Writing → GitHub main repo → GitHub Actions (CI) → Cloudflare Pages (deployment) → paulkuo.tw goes live
The middle three nodes all depended on GitHub. GitHub Actions was the key trigger for Cloudflare Pages auto-deployment. In other words, I couldn’t even publish to paulkuo.tw because deployment wasn’t running on my own machine.
Worse still, I had never thought about dismantling this chain before. It “just worked this way,” and this design was the default in engineering circles. When GitHub was alive, the entire flow was so smooth it made you forget its single point of failure nature.
Until 4/29, when this nature was exposed.
What Does the Three Mile Island Accident Teach Us?
On March 28, 1979, at dawn, the Three Mile Island Nuclear Plant in Pennsylvania experienced the most severe civilian nuclear accident in U.S. history. It started when the secondary system’s main feedwater pumps stopped working, causing pressure in the primary system to spike rapidly. The pressure relief valve (PORV) that should have automatically closed got stuck open, causing continuous coolant loss.
But the instrumentation misled the control room: the PORV indicator only showed “command sent” rather than “valve closed,” making operators think the valve was closed. Seeing the pressurizer water level rise, thinking there was too much coolant, they actually shut down the high-pressure injection system. As a result, coolant continued leaking through the stuck valve, causing the core to gradually overheat and partially melt.
The accident wasn’t caused by a single error, but three small problems accumulating simultaneously, making it impossible for on-site personnel to respond accurately in under a minute.
This incident later became the foundational case for Charles Perrow’s “Normal Accidents” theory. Perrow himself was one of the TMI accident investigators, and the first half of his 1984 book “Normal Accidents” is his step-by-step reconstruction of this accident. Perrow introduced two core concepts: “tight coupling” (when one component fails, it rapidly spreads to the next component) and “complex interactions” (different subsystems interact in unexpected ways). In such systems, small errors are rapidly amplified into major disasters. This isn’t about whether errors occur, but that they will inevitably occur.
What should really be examined isn’t some operator’s mistake, but the entire system’s design and management approach.
We need not safety awareness, but safety systems.
By getting the system right, with buffers, margins, and stable loops, we can operate with confidence.
This principle applies not only to our internal systems, but also to the external systems we depend on. When you entrust your entire workflow lifeline to a single supplier, that supplier becomes part of your system. Its fragility is your fragility.
GitHub’s suspension was my own Three Mile Island.
Two-Week Rebuild: paulkuo.tw’s Five-Layer Resilience Architecture
From 4/29, I decided I couldn’t just depend on GitHub. I planned and built the resilient system needed for “executing engineering through AI,” continuously evolving until 5/12 when I finally verified the publishing functionality was online. The architecture has five layers, each designed around the principle of “can’t let any single service become a chokepoint.”
Complete bird’s eye view:
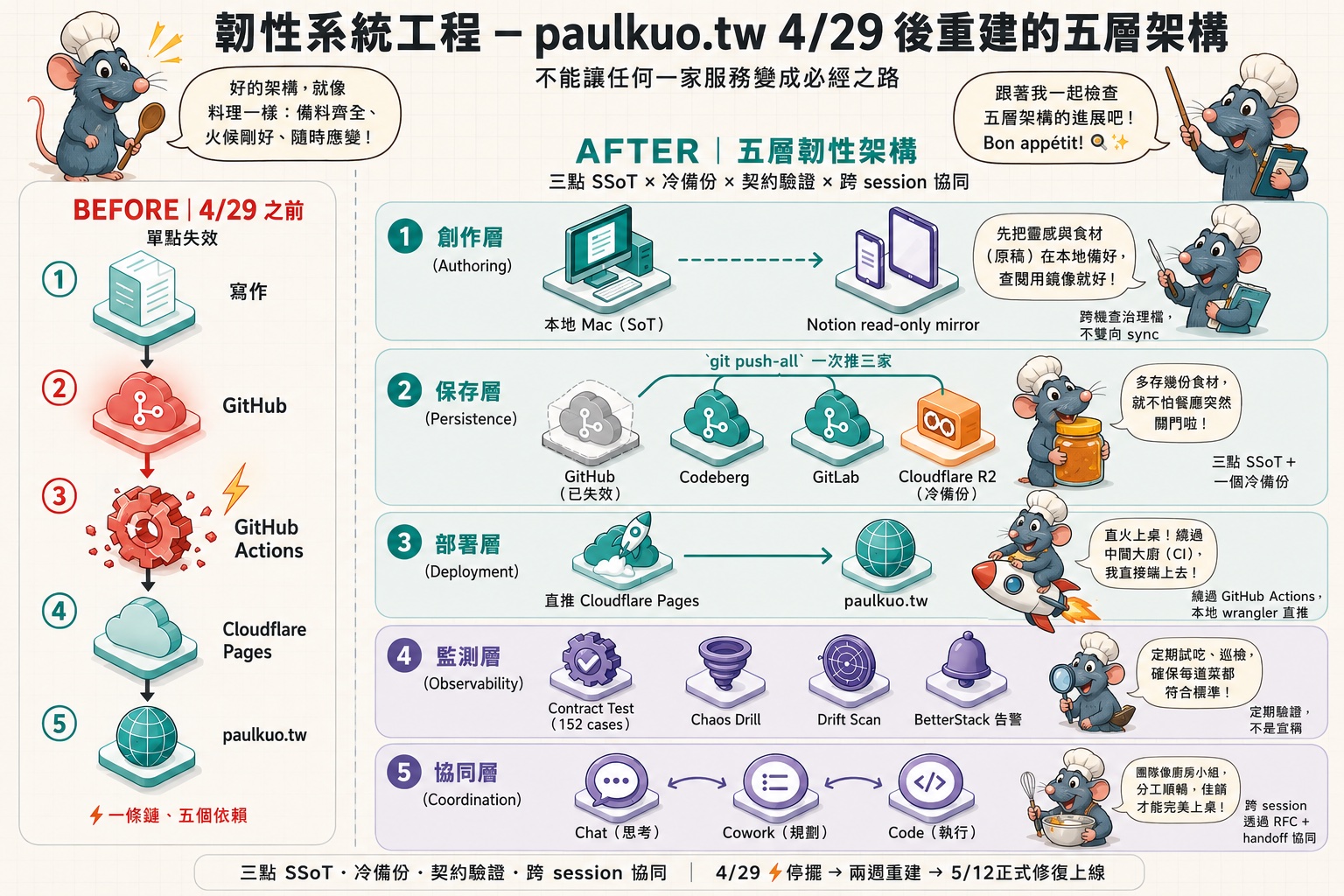
① Authoring Layer
Local Mac is the true source of truth, Notion is just a read-only mirror that lets me check governance files across phone, iPad, and machines—no bidirectional sync.
This logic is important: I used to think “Notion is in the cloud, syncs across machines, has version history, so naturally it’s the SoT.” But this assumes Notion will always be alive. After the incident, I flipped the thinking: the true source should be somewhere I have complete control, which is my local Mac. Notion steps back to be the display layer—if it breaks, it won’t block me.
② Persistence Layer
Three-point SSoT + one cold backup:
- Codeberg (European open-source Git host)
- GitLab (commercial Git host)
- Local Mac (master copy)
- Cloudflare R2 (offline cold backup, storing repo bundles and memory snapshots)
I set up a git push-all alias—one command pushes to all three simultaneously. GitHub origin stays in the remote list, but every push fails. I deliberately keep it as a “monument to the incident’s origin,” reminding myself how this architecture came about. When it’s restored later, I’ll still use it.
R2 is the fourth insurance beyond Git hosts. If all three Git hosts go down simultaneously (extremely unlikely but theoretically possible), the bundle is still in Cloudflare object storage.
③ Deployment Layer
Use wrangler to push directly from local to Cloudflare Pages, bypassing GitHub Actions. The entire deployment pipeline is completely decoupled from GitHub’s availability.
This is the most easily overlooked link in engineering. Many people forget that CI is also GitHub when rebuilding Git redundancy. Decoupling the deployment pipeline is more critical than Git mirroring, because you can slowly fix Git, but if deployment breaks you can’t even publish.
④ Observability Layer
Resilience needs regular validation:
- Contract testing 152 endpoints: LaunchAgent automatically runs once daily, comparing actual API behavior with spec definitions for drift
- Chaos drill: H1 exercise runs weekly, deliberately breaking a critical node to see if the system can auto-recover
- Drift scanning: automatically detects if endpoints are secretly added or modified without being written into specs
- BetterStack alerts: contract test failures push to BetterStack, then email and SMS notify me
This layer is the most easily underestimated part of this system. Without this layer, the “resilience” of the first three layers is merely claimed; with this layer, resilience is validated daily.
⑤ Coordination Layer
This layer handles not infrastructure, but human-AI collaboration methods.
I use three types of AI sessions for division of labor:
- Chat (thinking): problem decomposition, finding direction, discussing architecture
- Cowork (planning): organizing documents, planning tasks, producing work orders
- Code (execution): turning plans into code, implementing features, running tests
The three coordinate through RFC mechanism + handoff documents + shared pending queue (PENDING.md). I designed a session-handoff skill as the discipline for this collaboration: every session must end by writing a formatted handoff, and the next session opens by reading the handoff to take over.
This resilient architecture wasn’t created by giving commands for AI to help me build. It took two weeks of my trial and error pain, iterating with three types of sessions, more trial and error, correcting processes until it gradually took shape—and it’s still being modified.
Why “Build an AI Employee System in One Week” Doesn’t Work for Me?
During the two-week rebuild, I had a strong feeling:
Those “build an AI employee system in one week” courses or ready-made Skills packages on the market might work for others, but not for me.
I’ll use an analogy: each Skill is like a protein. What shape a protein folds into and what function it performs depends on its cellular environment, pH level, and interactions with other proteins. Proteins need to fold into different shapes to do different things.
Skills are the same. The same set of “writing skills,” “deployment skills,” “customer service skills” will fold into completely different shapes when given to different enterprises or individuals. Because task boundaries and enterprise needs always differ. Personal and enterprise goals might be similar, but workflow gaps, data context, and decision priorities are all different.
So AI Agent system design requires spending significant time optimizing pipelines and internal parameters. It’s not about using some framework and being done—you need to iterate repeatedly in your own work scenarios.
I modified daily and took two weeks to complete. I’ve developed software, managed software engineering teams, and am starting to accumulate some AI collaboration experience. For people without this background, they might get stuck forever. Of course, they might also be faster. But it’s unlikely to be “give one prompt and everything automatically completes.”
Five Things I Learned from Two Weeks of Rebuilding
One: Resilient system design isn’t about making systems strong enough not to break, but allowing local failures with backup capability.
Nassim Taleb proposes a trichotomy in Antifragile: fragile (breaks under stress), robust (doesn’t break under stress), antifragile (gets stronger under stress). Traditional engineering pursues “robustness”—being strong enough not to break. But in a complex world, “robustness” is an illusion because you never know where the next stress will come from. What we should really pursue is resilience: when something breaks, it won’t drag down the whole, and it can still be fixed when broken.
My five-node single line was “fake robustness”: it operated smoothly and looked stable, but could only last until the first impact.
Two: Agents are powerful, but the scenario of “throw one command, leave the rest to AI” doesn’t exist yet.
Over two weeks I collaborated with AI for at least hundreds of rounds. AI’s execution ability far exceeds humans, but convergence ability (converging multiple divergent AI suggestions into one executable decision) is still a gap. Each round needs human intervention to do this.
Three: So there’s no fast food shortcut for individuals building AI employee systems.
Following from above. Skills are like proteins—their folding shape depends on your cellular environment. Others’ folding methods might not work for you. Your workflow, your aesthetics, your decision-making patterns will ultimately shape a system only you can use. This is why this article’s architecture can be referenced publicly, but copying it exactly won’t necessarily work for you.
Four: Resilient systems need Human in the Loop: indispensable in both design and execution phases.
The second point was about current AI capability limitations. This point is about design choice: even when AI capability is sufficient someday, humans should still occupy key nodes in resilient system design.
HITL (human in the loop) roles span two phases:
Design phase: architectural decisions, dependency boundaries, degradation strategies, what can break, what absolutely cannot break—these are all human judgments. AI can list options and expand trade-offs, but converging to a decision and taking responsibility for consequences is still human.
Execution phase: whether contract test results should be treated as “real problems,” whether bugs exposed by chaos engineering should be fixed immediately, whether endpoints flagged by drift scanning represent “legitimate evolution” or “spec gaps”—each requires human judgment. How well the system can recover ultimately depends on whether humans are present.
Resilient systems are not “fully automated” systems. They are systems where humans are deliberately placed at key nodes during design and continuously supervised by humans during execution. If you throw the whole thing to AI and don’t stay online, resilience is at most claimed. Until the first incident when AI gives you 5 possible root causes but none can make the call, you realize the problem was never that AI wasn’t strong enough—it’s that no one was present.
Five: AI accelerated the “manual labor” of software engineering, but simultaneously amplified another demand: the “decision density” requiring nuanced human judgment.
Programming time has shortened, but deciding what to write, why to write this way, when not to write, how to converge multiple AI suggestions into one solution—this decision density has increased. One hour of work might compress 30 micro-decisions, each requiring judgment.
I can’t think of a good name for now, so I’ll call it the “Judgment Economy.”
The Judgment Economy is Rising
Over the past decade, the market rewarded “execution ability”: people who could code, design, and run data saw salaries rise.
Over the next decade, the market might reward “judgment.” Because execution—AI can already help you reach a certain level.
I’ve seen this argument: the role of knowledge workers is transitioning from “Maker (executor)” to “Curator” and finally settling on “Judge.” Three positions correspond to three different types of scarcity. Being able to execute is becoming less scarce; executing well and with taste is still somewhat scarce; judging whether to do something, when to stop, and taking responsibility for consequences is most scarce.
On 4/29 when GitHub cut me off, I thought I lost some internet functionality. After thinking carefully, I realized I had given up architectural decision-making authority: what this system should look like, who to depend on, who not to depend on, how to validate, how to fix—these decisions should always have been mine, I just defaulted to outsourcing them before.
Two weeks later on 5/12 when articles could be uploaded again, I wasn’t particularly moved. Instead I thought of a phrase: you shouldn’t entrust your lifeline to one company or bet heavily on some system, then claim to be free.

💬 Comments
Loading...