TL;DR:4/29 GitHub 无预警停权,没有理由也没回信。两周重建出五层韧性架构:本地优先 × 三点 SSoT × 绕过 CI 直推 × 契约测试与混沌演练 × 跨 session AI 协同。核心教训是:不能让任何一家服务变成必经之路。这个原则不只适用于内部系统,也适用于你所依赖的外部服务。
2026 年 4 月 29 日,我准备推 commit 到 paulkuo.tw 的 repo,一直出现错误信息。后来上网看 GitHub,发现完全点不进 GitHub 账号(如图)。我一度以为只是暂时性的无法登录,过几小时就好。但,并没有(如截图)。
Access to your account has been suspended due to a violation of our Terms of Service. Please contact support for more information.
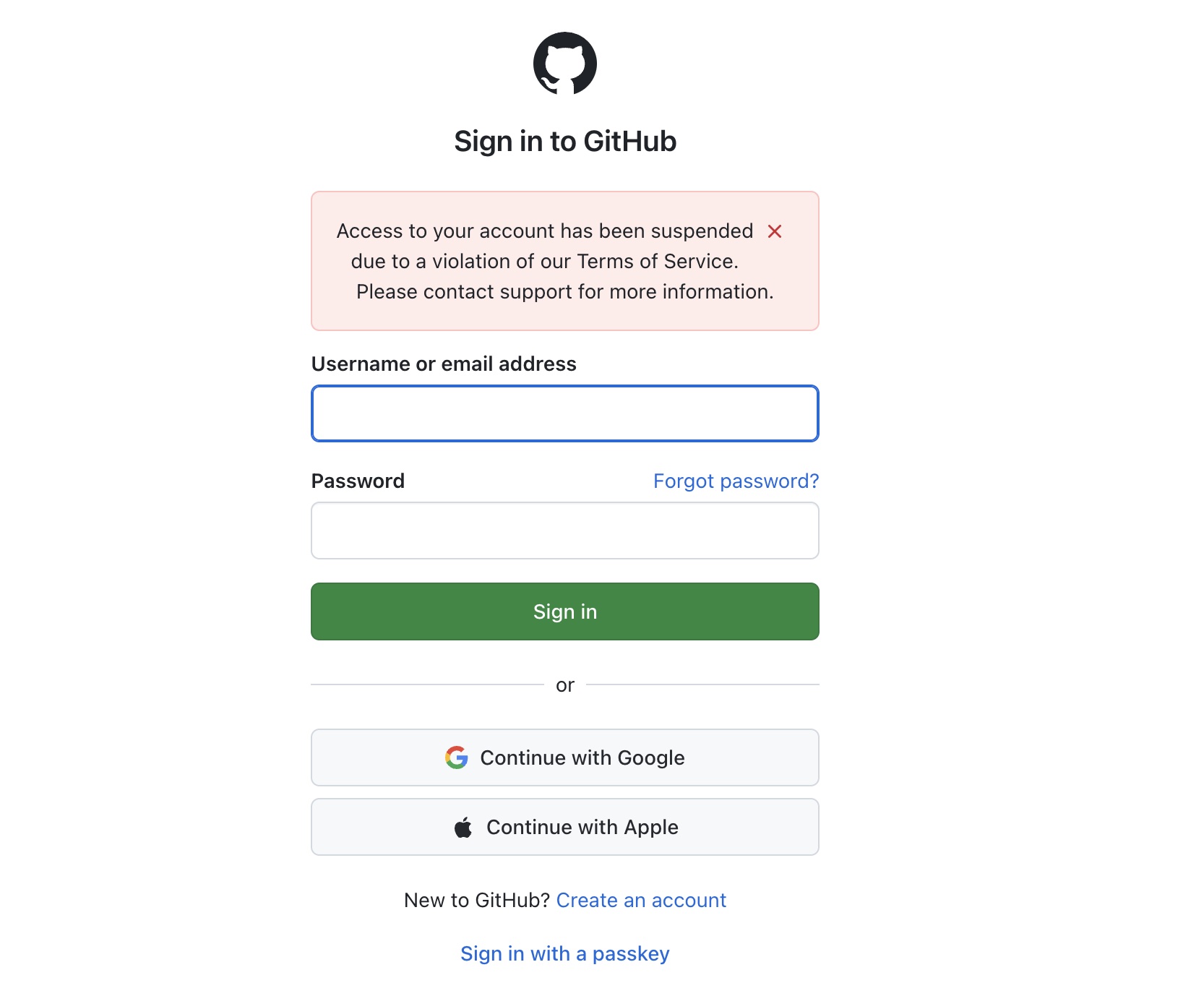
对 support 发了申诉信,到今天还没收到任何回复。
那时我才意识到,我把整个代码管理、CI、部署、甚至我的工作流核心,全部绑在一家公司身上有风险。这家公司刚刚把我阉了,不用给我理由。
为什么一家服务被停权,等于整个工作流被停权?
如果拆解我那天的工作链,会发现它是一条五个节点的单线:
写作 → GitHub 主仓库 → GitHub Actions(CI)→ Cloudflare Pages(部署)→ paulkuo.tw 上线
中间三个节点全部依赖 GitHub。其中 GitHub Actions 是触发 Cloudflare Pages 自动部署的关键。也就是说,我连 paulkuo.tw 都发不了文,因为部署这件事根本不在我自己的机器上跑。
更糟的是,这条链我以前从来没想过要拆解。它「就是这样运作」,工程师圈这样设计是默认值。当 GitHub 还活着的时候,整条流畅得让人忘了它有单点失效(single point of failure)的本质。
直到 4/29,这个本质暴露出来。
三哩岛事故告诉我们什么?
1979 年 3 月 28 日凌晨,美国宾州三哩岛核电厂发生美国史上最严重的民用核电事故。起因是次级系统的主给水泵停止运作,主系统压力急速上升。本应自动关闭的泄压阀(PORV)却卡住未关,导致冷却水持续流失。
但仪表显示误导了控制室:泄压阀的指示灯只显示「指令已发送」而非「阀门已关」,操作员误以为阀已关闭。看到加压器水位上升,以为冷却水过多,反而关闭了高压注水系统。结果冷却水从卡住的阀持续流失,炉心逐渐过热、部分熔毁。
事故并非单一错误造成,而是三个小问题同时累积,现场人员不可能在一分钟不到内做出准确的回应。
这起事件后来成为 Charles Perrow 「正常事故」(Normal Accidents)理论的开山案例。Perrow 本人就是 TMI 事故调查员之一,1984 年出版的《Normal Accidents》前半部就是他对这场事故的逐步重建。Perrow 提出两个核心概念:「紧密耦合」(一个环节出事会快速传染到下个环节)与「复杂性互动」(不同子系统会在意想不到的方式互相影响)。在这种系统里,小错误会被快速放大成大灾难。这不是有没有出错的问题,是「迟早会出错」的问题。
真正该被检讨的不是某个操作员的失误,而是整个系统的设计与管理方式。
我们需要的不是安全意识,是安全系统。
把系统搞好,有缓冲区,有余裕,有稳定的回路,我们才能有恃无恐。
这个道理不只适用于我们自己内部的系统,也适用于我们所依赖的外部系统。 当你把整条工作命脉托付给一家供应商,那家供应商本身就是你系统的一部分。它的脆弱,就是你的脆弱。
GitHub 的停权对我来说,就是我自己的三哩岛。
两周重建:paulkuo.tw 的五层韧性架构
从 4/29 起我就决定不能只依赖 GitHub,我规划并建置「通过 AI 执行工程」所需要的韧性系统,持续演化,到 5/12 才验收上线贴文的功能。架构分五层,每一层都针对「不能让任何一家服务变成必经之路」这个原则做了解耦。
完整鸟瞰如下:
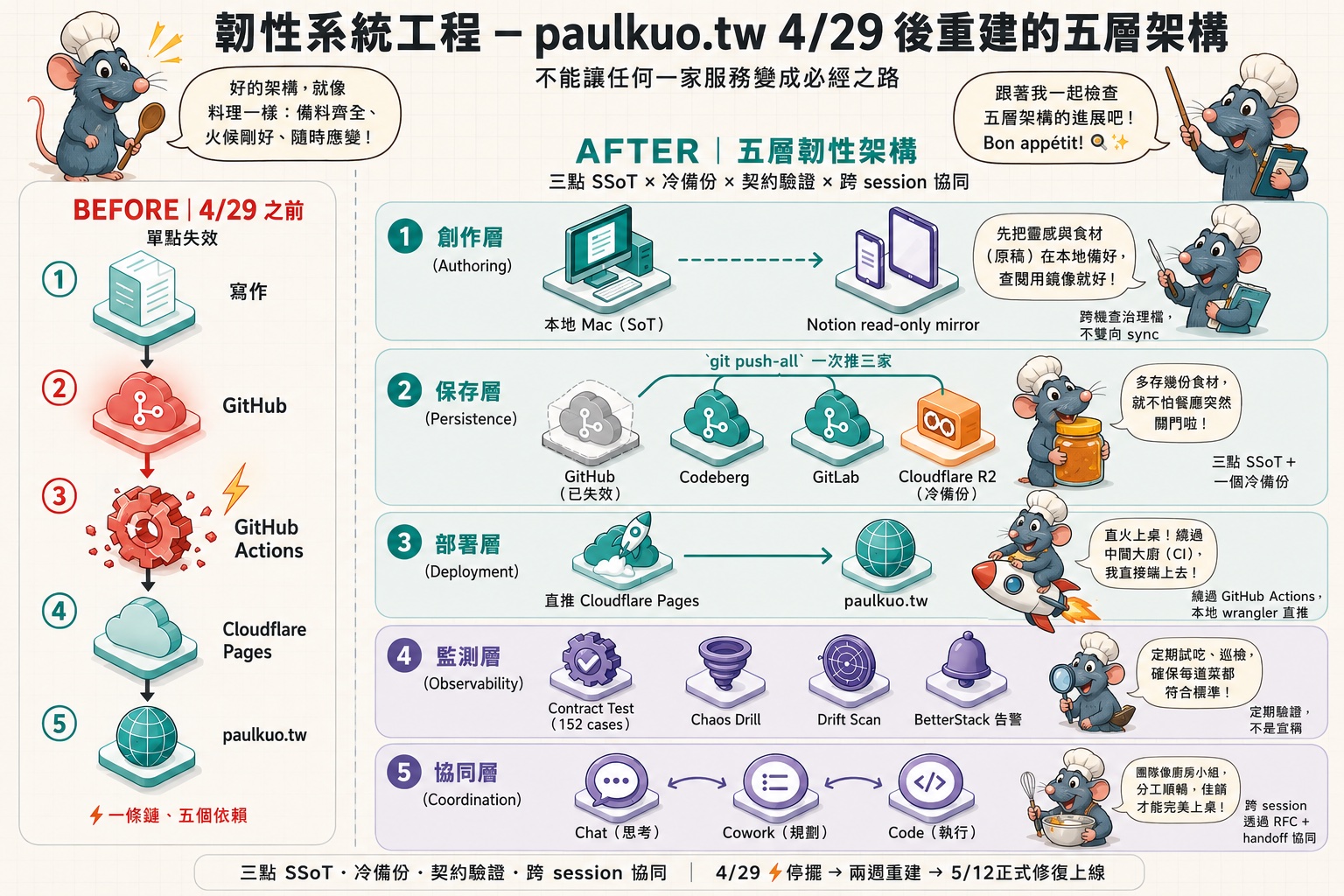
① 创作层(Authoring)
本地 Mac 是真正的原稿(source of truth),Notion 只是一个让我手机、iPad、跨机器能查治理文件的只读 mirror,不双向 sync。
这个逻辑很重要:以前我觉得「Notion 在云端、跨机器同步、有版本历史,自然是 SoT」。但这假设了 Notion 永远活着。事件后我反过来想:真正的原稿应该在我能完全掌控的地方,也就是本地 Mac。Notion 退一步当显示层,坏了也不会卡死我。
② 保存层(Persistence)
三点 SSoT + 一个冷备份:
- Codeberg(欧洲开源 Git host)
- GitLab(商业 Git host)
- 本地 Mac(master copy)
- Cloudflare R2(离线冷备份,存 repo bundle 与 memory snapshot)
我设了一个 git push-all alias,一个指令同时推三家。GitHub origin 留在 remote 清单里,但每次 push 都会 fail。我刻意保留它作为「事件起点的纪念碑」,提醒自己这个架构是怎么来的。等日后恢复,我一样会使用它。
R2 是 Git host 之外的第四份保险。万一三家 Git host 同时出事(极不可能但理论上会),bundle 还在 Cloudflare 对象存储里。
③ 部署层(Deployment)
用 wrangler 从本地直推 Cloudflare Pages,绕过 GitHub Actions。整条部署管线跟 GitHub 的存活完全脱钩。
这是工程上最容易被忽略的环节。很多人重建 Git 备援的时候,忘了 CI 也是 GitHub。部署管线的解耦比 Git 镜像更关键,因为 Git 你可以慢慢补,部署断了你连发布都做不到。
④ 监测层(Observability)
韧性需要定期验证:
- 契约测试 152 个 endpoint:每天 LaunchAgent 自动跑一次,比对实际 API 行为与规格定义有没有漂移
- 混沌演练(chaos drill):H1 演练每周跑一次,故意破坏一个关键节点,看系统能不能自动恢复
- 漂移扫描(drift scan):自动侦测有没有 endpoint 偷偷被新增或修改却没写进规格
- BetterStack 告警:契约测试失败会推到 BetterStack,再 email 以及 SMS 通知我
这层是这套系统最容易被轻视的部分。没这层,前三层的「韧性」是宣称出来的;有这层,韧性是每天被验证的。
⑤ 协同层(Coordination)
这层处理的不是基础设施,是人与 AI 的协作方式。
我用三种 AI session 形成分工:
- Chat(思考):问题拆解、找方向、讨论架构
- Cowork(规划):整理文件、规划任务、产出工单
- Code(执行):把规划转成代码、实作功能、跑测试
三者之间靠 RFC 机制 + handoff 文件 + 共享待办队列(PENDING.md)协同。我设计了 session-handoff skill 当作这套协作的纪律:每次 session 结束都要按格式写 handoff,下次 session 开场读 handoff 接手。
这套韧性架构不是下指令让 AI 帮我做出来。它是花了两周时间,在我的踩坑痛苦上,跟三种 session 反复磨合、再踩坑、修正流程才慢慢定型,而且还在修改。
为什么「一周建好 AI 员工系统」对我不适用?
两周重建的过程里,我有一个强烈的感受:
市面上那些「一周建好 AI 员工系统」的课程或现成 Skills 包,对别人可能行,对我不行。
我用一个比喻:每一个 Skill 像是一种蛋白质。蛋白质要折叠成什么形状、发挥什么功能,取决于它所处的细胞环境、酸碱度、其他蛋白质的互动。蛋白质要折成不同的形状,做出不同的事。
Skills 也一样。同一组「写作 skill」「部署 skill」「客服 skill」,丢到不同企业、不同个体手上,会折出完全不同的形状。因为任务边界与企业需求一定有相异之处。个人与企业的目标可能相似,但工作流的缝隙、数据的脉络、决策的优先序,全都不一样。
所以 AI Agent 系统设计,会需要花大量时间去优化管线与内部参数。不是用了某个 framework 就好,是要在你自己的工作场景里反复迭代。
我天天修改,才用两周跑完。我开发过软件,管理过软件工程团队,也开始累积一些 AI 协作的经验。对没有这些背景的人,或许会永远卡住。当然,也可能更快。但不太可能是给一个提示词,一切都自动完成。
两周重建,我学到的五件事
一、韧性系统的设计,不是让系统强到不会坏,而是允许局部坏掉、且能够补位。
Nassim Taleb 在《反脆弱》里提出三分法:脆弱(fragile,受到压力会坏)、强韧(robust,受到压力不坏)、反脆弱(antifragile,受到压力反而变强)。传统工程追求「强韧」,也就是强到不会坏。但复杂世界里,「强韧」是一种幻觉,因为你永远不知道下一个压力从哪来。真正该追求的是韧性:坏了不会拖垮整体,坏了还能修。
我那条五节点的单线就是「假强韧」:它运作很顺、看起来很稳,但只能撑到第一次冲击。
二、Agent 的能力强大,但「丢一句指令、剩下交给 AI」这种剧本目前还不存在。
两周里我跟 AI 来来回回协作了至少几百轮。AI 的执行力远超人类,但收敛能力(把多个分歧的 AI 建议收敛成一个可执行决策)目前还是断层。每一轮都需要人接手做这件事。
三、所以个体建置 AI 员工系统,没有速成的快餐。
承上。Skills 像蛋白质,折叠形状取决于你的细胞环境。别人的折法你拿来不一定能用。你的工作流、你的审美、你的决策模式,最后会塑造出一套只有你能用的系统。这也是为什么这篇文章的架构,公开出来大家可以参考,但你照抄不一定有效。
四、韧性系统需要 Human in the Loop:设计阶段与执行阶段都不能少。
第二件讲的是 AI 现在的能力限制。这条讲的是设计选择:就算哪天 AI 能力够了,韧性系统的设计里,人类仍应该占有关键节点。
HITL(human in the loop)的角色分两个阶段:
设计阶段:架构决策、依赖边界、降级策略、什么可以坏、什么绝对不能坏,这些都是人类要拍的判断。AI 能列选项、能展开 trade-off,但收敛到一个决策、为后果负责的还是人。
执行阶段:契约测试的结果要不要当「真实的问题」、混沌演练暴露的 bug 要不要立刻修、漂移扫描跳出来的 endpoint 是「合法演进」还是「规格漏洞」,每一笔都需要人类介入判断。系统能恢复到什么程度,最后看人有没有在场。
韧性系统不是「全自动」的系统。 它是设计阶段有意识让人类处于关键节点、执行阶段持续被人类监督的系统。如果把整套丢给 AI 跑、自己不上线,韧性最多只是宣称出来的。直到第一次出事,AI 给你 5 个可能的根因,但没有一个能拍板,你才发现问题从来不在 AI 不够强,是没人在场。
五、AI 加速了软件工程的「体力活」,但同时放大了另一种需求:需要人类细腻判断的「决策密度」。
编程的时间变短了,但要决定写什么、为什么这样写、什么时候不写、如何把多个 AI 的建议收敛成一个方案,这些决策密度变高了。一个小时的工作可能浓缩了 30 个微决策,每个都需要判断力。
我一时想不到好名字,姑且叫它「判断力经济」。
判断力经济正在崛起
过去十年,市场补贴的是「执行力」:会编程、会做设计、会跑数据的人薪水水涨船高。
未来十年,市场可能补贴的是「判断力」。因为执行这件事,AI 已经能帮你做到一个水准了。
我看过一个说法:知识工作者的角色,正在从「Maker(执行者)」过渡到「Curator(策展人)」、最后落脚在「Judge(裁判官)」。三个位置对应三种不同的稀缺性。做得出来,越来越不稀缺;做得到位、做得有品味,还算稀缺;判断该不该做、何时停下、为后果负责,最稀缺。
4/29 GitHub 把我断线,我以为我失去的是某一种网络功能。仔细想了一下,发现,我是把架构决策权放弃了:这套系统长什么样、依赖谁、不依赖谁、怎么验证、怎么修,这些决策从来都该是我的,只是以前我把它默认外包了。
两周后 5/12 文章可以开始上传,我没有特别感动。倒是想到一句话:不该把命脉托付给一家公司或者重压在某个系统,然后还声称自己是自由的。

💬 留言讨论
加载中...