
While scrolling Facebook, I came across Lucy’s post where she shared an open-source project investment scorecard (Lucy Chen, EIR at Singapore’s Zoo Capital, managing a fund with over $2 billion in assets under management).
Lucy’s framework was clear: five dimensions, weighted scoring, and veto mechanisms. The technical prowess that many developers take pride in still has many pitfalls when it comes to real business implementation.
Lucy’s framework comes from actual combat experience—she used this scorecard to flag the LMCache project before NVIDIA GTC, giving it a 7.78 “dark horse” rating. Two weeks later, when NVIDIA released Dynamo 1.0, LMCache was incorporated into the official integration list. Her investment scorecard can capture signals.
But I had another thought: Could this ruler be democratized for ordinary people?
A Different Perspective
Lucy Chen’s framework approaches from a VC investment angle. It considers exit paths, team internationalization, community governance, and capital efficiency. These are all critical questions for investors.
But for many individuals who independently build tools with AI, what if I have no intention of being invested in? What if I just want to build for joy? What if I have no plans to commercialize? What if this era is no longer suitable for selling small software tools?
For example, I’ve built real-time meeting translation tools, multi-model debate engines, and others—all created from scratch by me and Claude. I don’t need investment or exit strategies, but I do need “someone” to tell me about the value of what I’m building and the direction for adjustments.
This question is implicitly embedded in other dimensions in Lucy Chen’s framework. I wanted to make it independent.
Three Modifications
I made three changes.
First, removed the “team capability” dimension. Teams are important components of companies. But I wanted to focus on service evaluation—in the future, one person might create ten products, making this dimension less discriminating. I extracted it as a non-scoring “Builder Profile” preliminary field—for AI reference without affecting the total score.
Second, added a “problem-solving power” dimension. Is the problem you’re solving something you imagined, or have five or more people independently described this pain point? What are the existing alternative solutions? How much better is your solution than existing ones—10x better or slightly better? These questions should be the first asked of any builder before they start coding.
Third, made the commercialization dimension stage-adaptive. It’s unfair to ask a side project still in concept phase “what’s your monthly recurring revenue,” but it’s reasonable to ask “have you thought about how to make money” or “recommend to market.” I let users first select their product stage—concept, launched, has users, has revenue—different stages see completely different evaluation signals.
After modifications, the five dimensions became: Problem-Solving Power (25%), Market Validation (20%), Technical Moat (20%), Commercialization Path (20%), Long-term Sustainability (15%). Each dimension has 4-6 signals, each signal scored 0-10, weighted to calculate the total score.
5.01 Points—Slapped by My Own Ruler
After designing the framework, I ran a complete evaluation on my own real-time translation tool.
Result: 5.01/10. Red light.
The score distribution was a very typical engineer product profile: Problem-Solving Power 7.0, Technical Moat 6.2 (three-engine STT routing, exclusive corpus accumulation), Long-term Sustainability 5.5, but Market Validation 4.0 (no external user revisit data), Commercialization 2.0 (almost no monetization plan).
The radar chart shape was severely skewed—the problem-solving and technical corners extended outward, while the market and commercialization corners were almost flat against the floor.
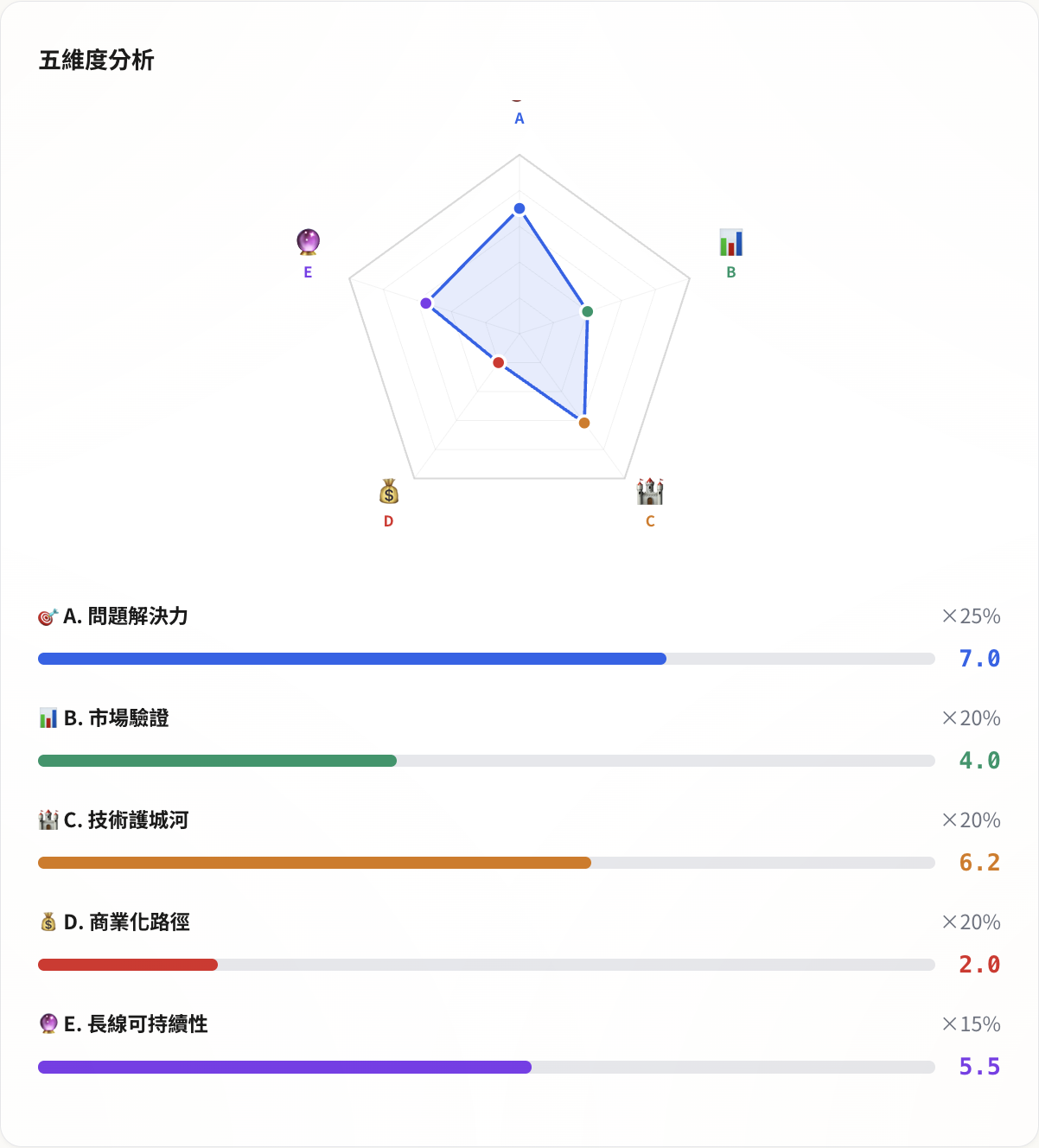
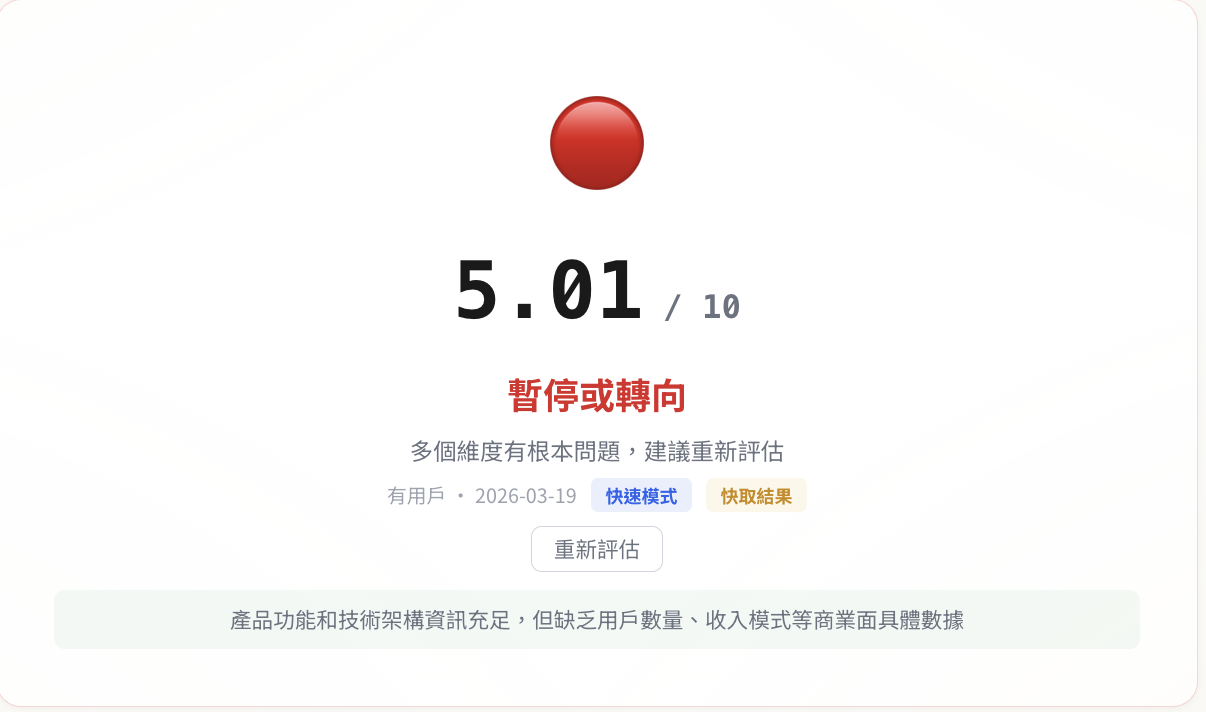
This result was correct (though somewhat jarring to look at). The low score was because it told the truth: good technology doesn’t equal a well-made product. I spent time on Qwen3-ASR and Deepgram routing logic, but hadn’t particularly considered “who would pay for this.” Because at this stage, I indeed had no plans to charge.
So this ruler was honest, with no illusions.
Survey the Market Before Coding
Following convention, I did market reconnaissance before writing code.
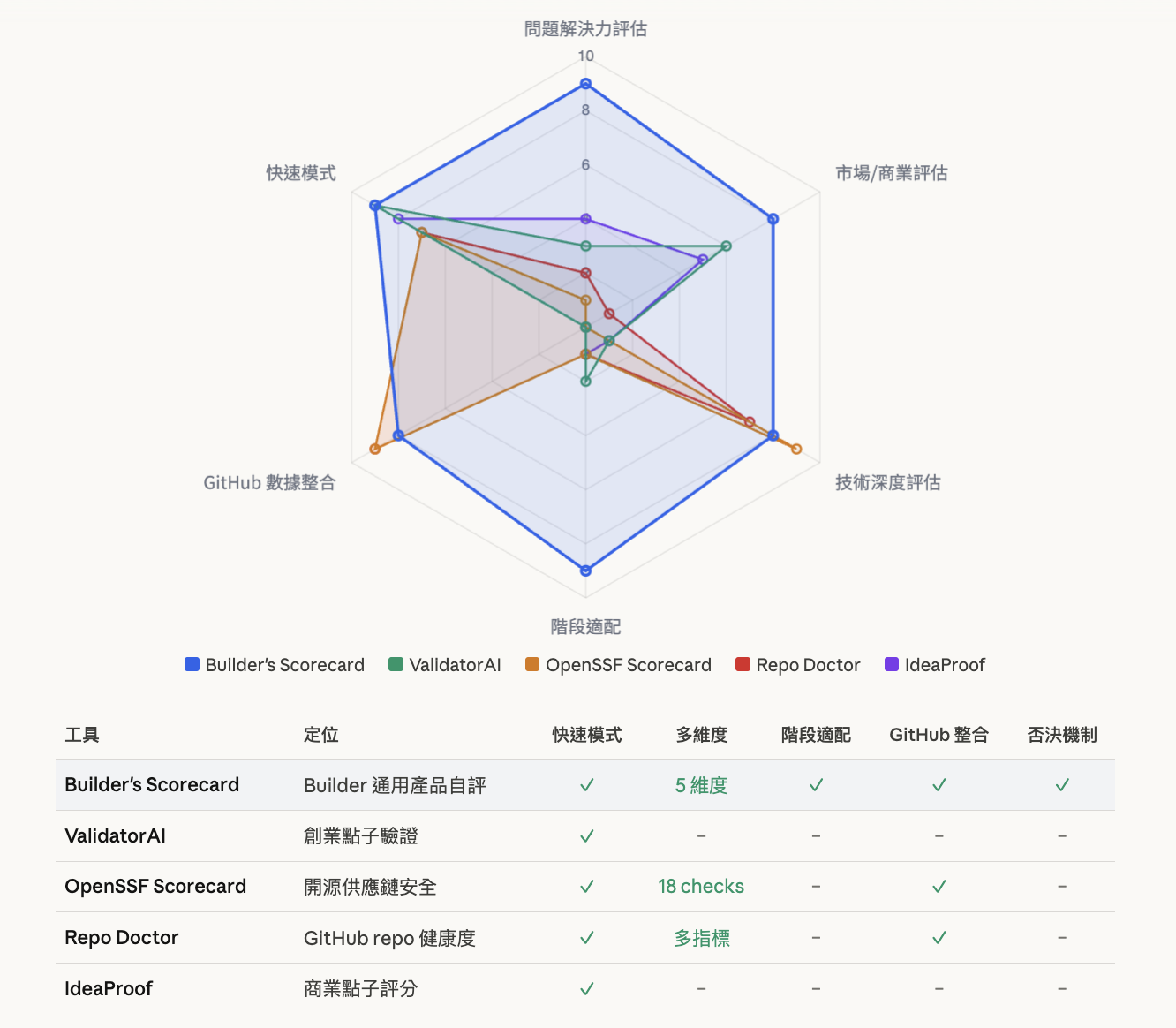
I found some similar services, such as ValidatorAI that lets you paste a sentence to validate startup ideas, accumulating over 300,000 uses. OpenSSF Scorecard specifically evaluates open-source project supply chain security. Repo Doctor uses GitHub API to automatically extract structured data for health analysis.
Each had something worth learning: ValidatorAI’s “results in 30 seconds” lowered the usage barrier, directly inspiring the quick mode design; OpenSSF’s score interpretation mechanism reminded me that low scores don’t mean “bad”—you need to help users interpret correctly; Repo Doctor’s GitHub structured data extraction lets AI focus on parts requiring judgment.
But no existing tool accomplished what I wanted to do (perhaps my research wasn’t thorough enough): use one framework to simultaneously evaluate a product from five dimensions, whether it’s an open-source tool, SaaS, or internal system.
After confirming market positioning, I started coding.
One Day, Five Phases
From seeing the post to having the impulse to execute took one day. The entire development was completed through AI collaboration—Chat sessions for reconnaissance and planning, Code sessions for programming, Cowork sessions for batch processing and state management.
Phase 1 built the core framework: five dimensions × 30 signals frontend interface, SVG radar charts, quick and complete modes, bilingual Chinese-English switching, Markdown and JSON export. Pure frontend, no API calls.
Phase 2 integrated AI: used Claude API for two things—Prompt A automatically scores 30 signals based on user-submitted product descriptions (temperature = 0, ensuring stable scores for multiple runs of the same product), Prompt B generates strategic recommendations based on evaluation results (temperature = 0.3, allowing recommendation variation).
Phase 3 expanded input sources: supported four inputs—plain text descriptions, GitHub URLs (automatically extracts structured data like stars/contributors/forks/license then sends to AI for evaluation), README file uploads, general website URL extraction.
Phase 4 implemented protection and social features: four-layer defense architecture (Rate Limit, Auth Gate, Result Cache, Daily Cost Cap) to prevent abuse after opening. Added storage functionality, dynamic wall, share links, making evaluation results discoverable and discussable.
Phase 5 final polish: added entry cards to homepage, methodology introduction page, SEO enhancement (JSON-LD + FAQ Schema), llms.txt updates.
No skipping between phases—Phase 2’s AI prompt format had to align with Phase 1’s data structure, Phase 3’s GitHub data had to feed into Phase 2’s prompts. Reconnaissance before action, planning before execution.
The Ruler’s Discriminative Power
After the tool went live, I tested it with three completely different products.
LangChain: 8.02 points. 130,000 stars, 3,659 contributors, LangSmith paid product. All five dimensions above 7 points, only long-term sustainability slightly lower due to big tech threats.
Lucy Chen’s OSS Investment Scorecard itself: 6.82 points. Solid framework design, real problems, 233 stars at test time, 2 contributors, zero revenue model.
My real-time translation tool: 5.01 points. Technical foundation solid, market and commercialization blank.
Three products, three completely different radar chart shapes. Scores were discriminating, and the discrimination direction matched observations. This ruler should have decent discriminative power.
The Score Isn’t the Point
In 2026, one person plus AI can indeed push an idea from concept to a truly live tool within days. Shipping fast doesn’t mean what shipped deserved to exist.
In post-AI society, the barriers to building tools are rapidly lowering. More and more people can become builders. But the question surfaces right here: Are the tools we create truly suitable for human use? Do they actually solve problems?
When an idea first emerges, or when a product is halfway done, do we have the ability to keep moving forward while stopping to check: Is this something worth creating? Does it serve human needs, or does it only satisfy our impulse to “be able to build it”?
Builder’s Scorecard doesn’t aim to give “correct answers.” It puts data from five dimensions in front of you, letting you judge for yourself.
What matters isn’t just the total score, but the shape of the radar chart. A 6.0-point product with balanced five corners might be healthier than a 7.0-point product with one dimension at 1. But it might also be intentional. On the path of creation, everything is beautiful. Ugly posture doesn’t matter—just keep moving forward.
If you’ve also built some tool or side project, come measure it. Not for the score, but to see your blind spots.

💬 Comments
Loading...