
在 Facebook 滑到Lucy的贴文,她分享一套开源项目投资评分卡(Lucy Chen,新加坡 Zoo Capital 的 EIR,管理规模超过 20 亿美金的基金)。
Lucy分享的框架很清楚:五个维度、加权计分、一票否决机制。很多开发者一直引以为傲的技术,在真实商业落地中还有很多坑。
Lucy 的框架来自实战——她在 NVIDIA GTC 之前就用这套评分卡标记了 LMCache 这个项目,给出 7.78 分的「黑马」评级,两周后 NVIDIA 发布 Dynamo 1.0 就把 LMCache 收编进官方集成名单。她设计的投资评分卡能抓到信号。
但我也有另一个念头:这把尺是否能普惠寻常大众?
换个角度
Lucy Chen 的框架是从 VC 投资角度出发的。考虑出场路径、团队国际化、社群治理、资本效率。这些对投资人来说都是关键的问题。
但对许多靠AI独立做工具的个人来说,如果我压根没有想被投资?如果我只是想做开心?如果我没有要商转?如果这时代已经不适合贩售软件小工具?
例如,我做了即时会议翻译工具、多模型辩论引擎等,都是我一个人加上 Claude 从零做起的。我没有被投资的需要,不需要有退出路径,但我需要有”人”告诉我:做的这个东西的价值与调整方向。
这个问题在 Lucy Chen 的框架里被隐含在其他维度里。我想独立出来。
三个改动
我做了三件事。
第一,拿掉「团队能力」维度。团队是公司的重要组成。但我想针对服务评估,日后一个人可能做十个产品,这个维度可能就没有鉴别力。我把它抽离成一个不计分的「Builder Profile」前置栏位——留给AI参考,不影响总分。
第二,新增「问题解决力」维度。你解决的问题是你自己假想的,还是真的有五个以上的人独立描述过这个痛点?现有替代方案是什么?你的解法比现有方案好多少——是 10 倍还是略好?这些问题应该是任何 builder 在动手之前第一个被问的。
第三,商业化维度做了阶段适配。一个还在概念期的 side project 被问「月经常性收入多少」是不公平的,但被问「你有没有想过怎么赚钱」、「推荐到市场」是合理的。我让使用者先选产品阶段——概念期、已上线、有用户、有收入——不同阶段会看到完全不同的评估信号。
改完之后,五个维度变成:问题解决力(25%)、市场验证(20%)、技术护城河(20%)、商业化路径(20%)、长线可持续性(15%)。每个维度下面有 4-6 个讯号,每个讯号打 0-10 分,加权算出总分。
5.01 分——被自己的尺打脸
框架设计完,我用自己的即时翻译工具跑了一次完整评估。
结果:5.01 / 10。红灯。
分数分布是非常典型的工程师产品轮廓:问题解决力 7.0 分,技术护城河 6.2 分(三引擎 STT 路由、独家语料累积),长线可持续性 5.5 分,但市场验证 4.0 分(没有外部用户回访数据),商业化 2.0 分(几乎没有收费计划)。
雷达图的形状严重偏科——问题解决力和技术那两角撑出去,市场和商业化那两角几乎贴在地板。
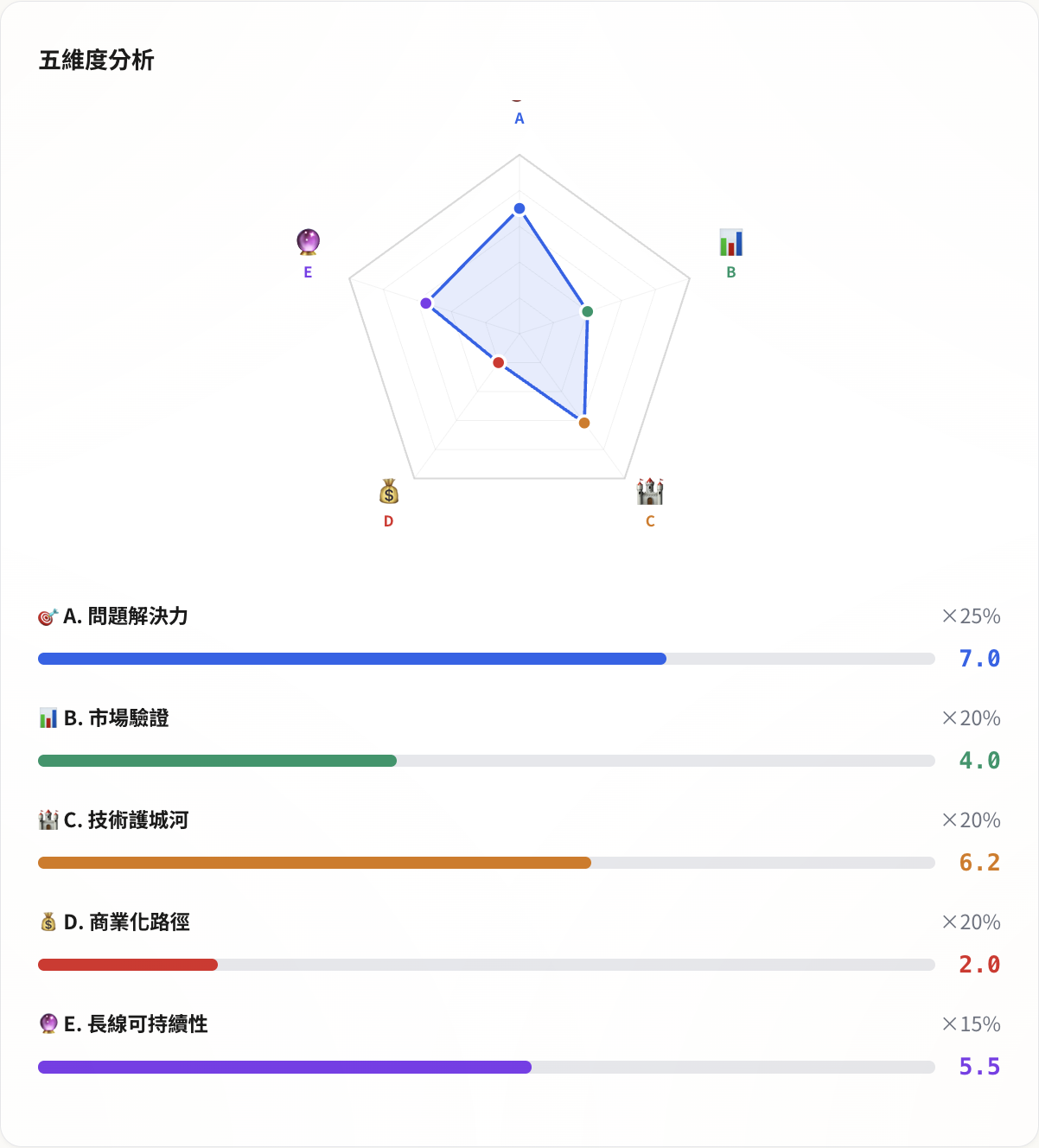
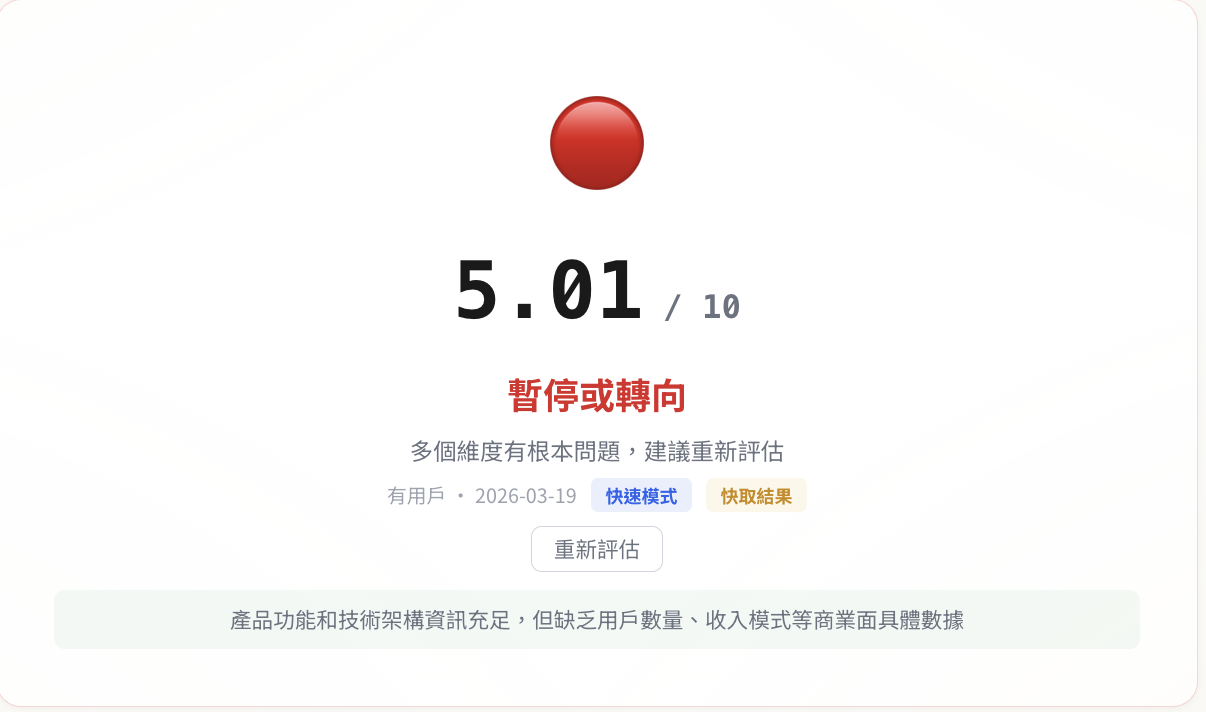
这个结果正确(虽然看起来有点刺眼),分数低是因为它说出事实:技术好了不等于产品做好。我花时间在 Qwen3-ASR 和 Deepgram 的路由逻辑上,但还没特别想过「谁会为这个付钱」。因为我在这个阶段确实没有收费的打算。
所以,这把尺诚实,没有幻觉。
先看市场再动手
依照惯例,在动手写代码前先做市场侦察。
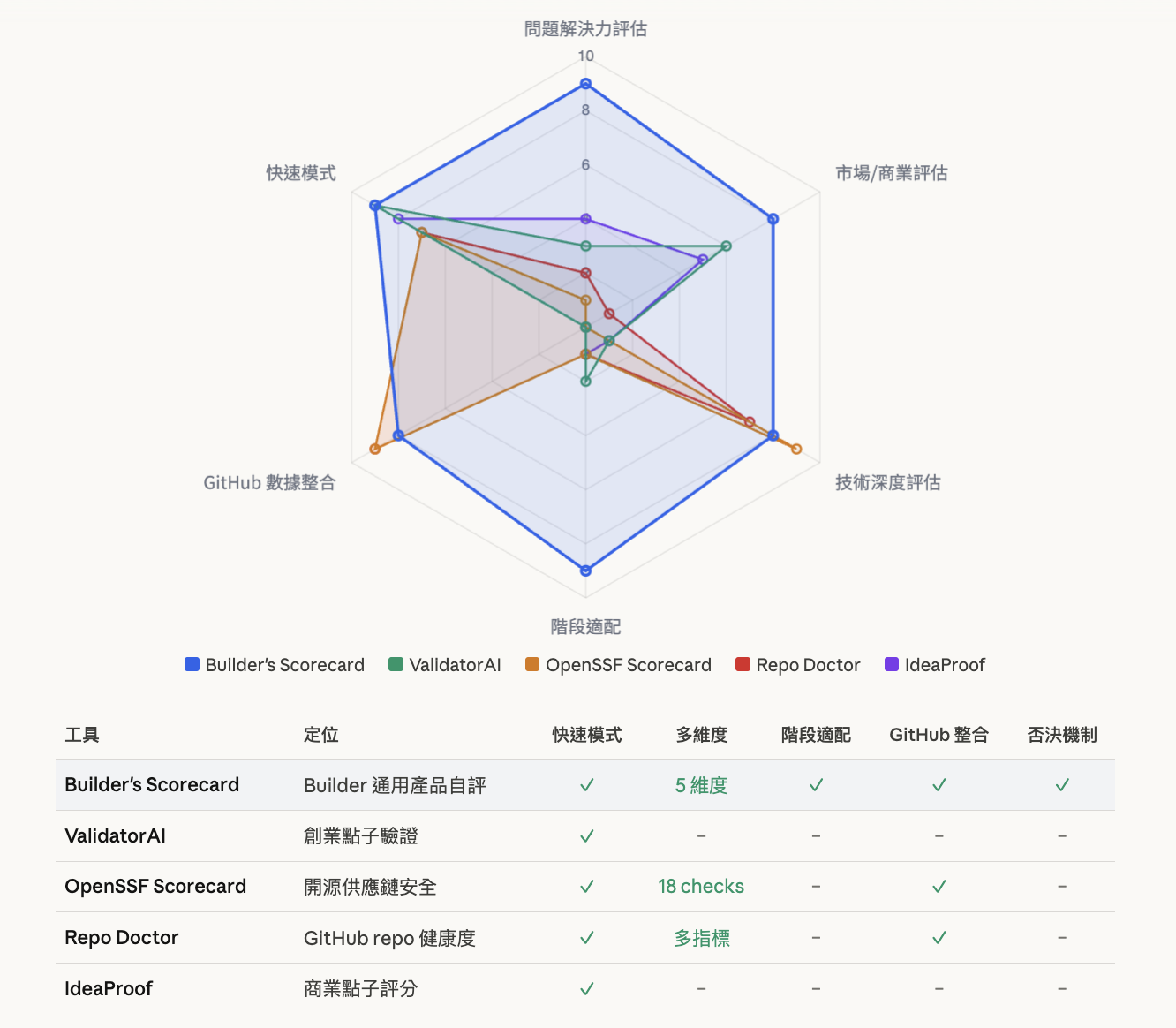
找到一些类似服务,例如 ValidatorAI 让你贴一句话就能验证创业点子,累积超过 30 万次使用。OpenSSF Scorecard 专门评估开源项目的供应链安全。Repo Doctor 用 GitHub API 自动抓结构化数据做健康度分析。
每一个都有值得学的地方:ValidatorAI 的「30 秒出结果」降低了使用门槛,这直接启发了快速模式的设计;OpenSSF 的分数解读机制提醒我——低分不代表「不好」,要帮使用者正确解读;Repo Doctor 的 GitHub 结构化数据撷取让 AI 可以专注在需要判断力的部分。
但没有一个现成的工具完成我想做的事(也许我的调查不够):用一套框架,从五个维度同时评估一个产品,不管它是开源工具、SaaS、还是内部系统都适用。
确认了市场定位后,我开始写代码。
一天,五个阶段
从看到贴文到起心动念去执行,是一天。整个开发用 AI 协作完成——Chat session 做侦察和规划,Code session 写代码,Cowork session 处理批次作业和状态管理。
Phase 1 做核心框架:五维度 × 30 个讯号的前端界面、SVG 雷达图、快速模式和完整模式、中英双语切换、Markdown 和 JSON 导出。纯前端,不碰 API。
Phase 2 接入 AI:用 Claude API 做两件事——Prompt A 负责根据使用者贴的产品描述自动为 30 个讯号打分(temperature = 0,确保同一个产品跑多次分数稳定),Prompt B 负责根据评估结果生成策略建议(temperature = 0.3,允许建议有变化)。
Phase 3 扩充输入源:支持四种输入——纯文字描述、GitHub URL(自动抓 stars / contributors / forks / license 等结构化数据再送 AI 评估)、README 文件上传、一般网站 URL 撷取。
Phase 4 做防护和社交:四层防御架构(Rate Limit、Auth Gate、Result Cache、Daily Cost Cap)确保开放后不会被滥用。加上存储功能、动态墙、分享链接,让评估结果可以被发现和讨论。
Phase 5 收尾打磨:首页加入口卡片、方法论介绍页、SEO 强化(JSON-LD + FAQ Schema)、llms.txt 更新。
每个 Phase 之间不跳步——Phase 2 的 AI prompt 格式要对齐 Phase 1 的数据结构,Phase 3 的 GitHub 数据要喂进 Phase 2 的 prompt。先侦察再动手,先规划再执行。
尺规的鉴别力
工具上线后做测试:拿三个完全不同的产品跑评估。
LangChain:8.02 分。13 万 stars、3,659 contributors、有 LangSmith 付费产品。五个维度都在 7 分以上,只有长线可持续性因为大厂威胁稍低。
Lucy Chen 的 OSS Investment Scorecard 本身:6.82 分。框架设计扎实、问题真实,测试时 233 stars、2 个 contributor、零收入模式。
我的即时翻译工具:5.01 分。技术面有底子,市场面和商业化是空白。
三个产品,三种完全不同的雷达图形状。分数有区分度,而且区分的方向符合观察。这把尺应该有一定的鉴别力。
重要的不是分数
在 2026 年,一个人加上 AI,确实可以在几天内,把一个想法从概念推进成真正上线的工具。能快速上线,不代表上线的东西值得被做出来。
在后 AI 社会里,打造工具的门槛正在快速降低。越来越多人都可能成为 builder。问题也从这里浮出水面:我们做出来的工具,真的适合人使用吗?真的有解决问题吗?
当一个念头刚开始浮现时,或当产品做到一半时,我们是否有能力一边前进,一边停下来检查:这是不是一个值得被做出来的东西?它服务的是人的需求,还是只是满足了我们「能做出来」的冲动?
Builder’s Scorecard 不是要给”正确答案”。它把五个维度的数据摆在你面前,让你自己判断。
重要的不只有总分,还有雷达图的形状。一个 6.0 分但五角均匀的产品,比一个 7.0 分但某个维度是 1 的产品可能更健康。但,也可能是你刻意为之。在创造的路上,一切都是美好的。姿势丑没关系,继续前进就好。
如果你也做了什么工具或 side project,来量一下。不是为了分数,是为了看见自己的盲区。

💬 留言讨论
加载中...