
TL;DR — Claude Fable 5’s significance isn’t just another model upgrade, but enabling already-running AI workflows to enter the long-task agent phase. Fable 5 and Mythos 5 can autonomously execute longer, more complex tasks than any previous Claude model, with the advantage becoming more pronounced as tasks grow longer and more complex. Through dynamic safety routing, it preserves full capability for general tasks while only delegating to Opus 4.8 in high-risk scenarios. The real watershed is no longer whether you use AI, but whether you can integrate AI into your workflow to form a continuously operating, manageable productivity system.
Last week when publishing an article, I had four AI windows open simultaneously. One was modifying the frontend, another running translations, a third synchronizing governance records, and the fourth discussing with me how that paragraph should be written. I clearly realized I wasn’t “using” AI, but “orchestrating” a group of AI workers with different capabilities. At that moment, they seemed more like new life forms rather than tools to me: they could move autonomously, grow independently, and sometimes step on each other’s toes. Only after publishing the article did I more clearly recognize that I was no longer managing scattered individual tasks, but an entire work order that operates itself and occasionally generates internal conflicts.
On June 9, 2026 (today), Anthropic released Claude Fable 5. On the surface, it’s just a new model version; but for someone like me who orchestrates AI daily and integrates AI into research, writing, judgment, and decision-making processes, it’s a signal: AI workflows that previously required manual decomposition, handoffs, corrections, and gap-filling can be optimized again to enter the next phase. Fable 5 makes already-operating AI work systems more capable of long-term operation, more stable, and closer to true autonomous collaboration.
Why Is Fable 5’s Real Value Safety Routing Rather Than Raw Capability?
What’s worth noting this time isn’t just how much model capability has improved, but how Anthropic uses a two-tier architecture to govern frontier model capabilities. One tier is Claude Fable 5, targeting general users and enterprise markets; the other is Claude Mythos 5, with fewer capability restrictions but only open to trusted security defenders and critical infrastructure. Both share the same underlying model, differing only in guardrails. Officials even specifically explained the naming: Fable comes from Latin fabula, meaning “that which is told,” sharing origins with Greek Mythos. Using two synonymous words to name the same underlying model actually clarifies one thing: the difference lies mainly in safety guardrails, not underlying capability.
This tiered design reflects that frontier AI can no longer be understood through general product logic alone. When model capabilities reach levels involving cybersecurity, biochemistry, software engineering, and long-task autonomous execution, they’re no longer just general consumer tech products, but production tools with real-world impact. The same capability can help defenders patch vulnerabilities or potentially lower barriers for attackers; it can accelerate pharmaceutical and life science research or potentially touch high-risk dual-use issues.
So what’s most worth observing about Fable 5 is its safety routing mechanism. Previously, many models became conservative for safety reasons, often making general users feel capabilities were diminished. Fable 5 takes a different path: preserving full capability for regular tasks as much as possible, only switching to the more conservative Claude Opus 4.8 when the system detects high-risk requests like cybersecurity, biochemistry, or model distillation, while notifying users. Official data shows over 95% of conversations never trigger such fallbacks, and in those conversations, Fable 5 performs equivalently to Mythos 5.
This represents AI companies testing new governance logic: rather than making the entire model less intelligent, they’re doing dynamic downgrading in high-risk scenarios. I can understand the trade-offs behind this design. For someone working with AI, the biggest fear isn’t that models have boundaries, but that models become constrained everywhere while trying to maintain boundaries. If downgrading can truly be limited to less than 5% of conversations, it means most daily work can still leverage the strongest tier of capability rather than sacrificing overall user experience for rare high-risk scenarios.
Why Does This Mark the Beginning of AI Industry Maturation?
Behind this is actually the starting point of AI industry maturation. When models were just chat tools, competition focused on how natural responses were, how fast they were, how cheap they were. But when models begin executing long tasks, understanding large codebases, organizing complex documents, participating in financial analysis, and assisting legal reviews, competitive standards shift.
How dramatically will these standards shift? In Anthropic’s early testing, Stripe used Fable 5 for a full codebase migration on a fifty-million-line Ruby codebase—work that would take an entire team over two months was completed by the model in one day. This is no longer “filling in a few lines of code” level, but beginning to take on entire work chains.
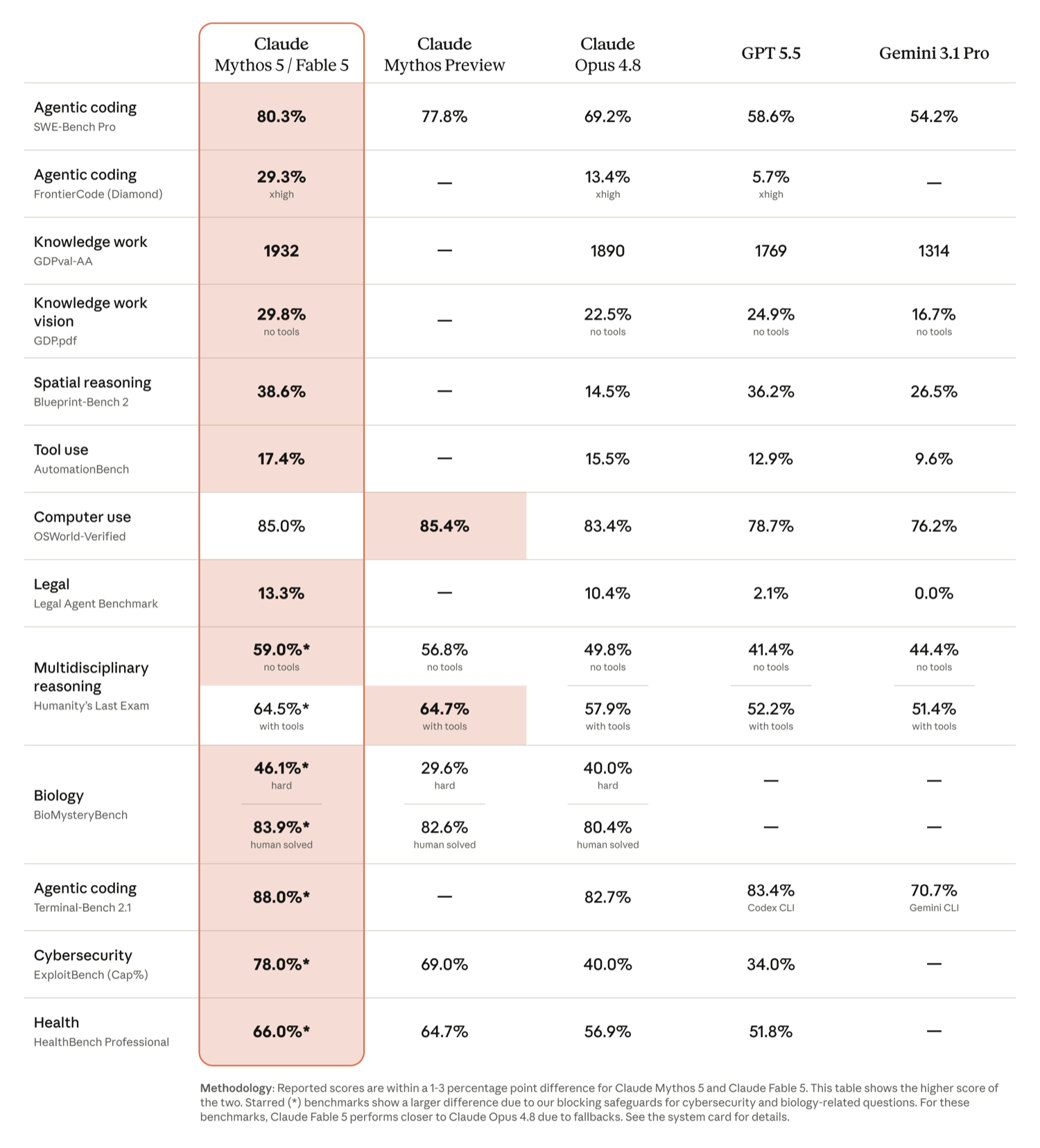
Claude Fable 5/Mythos 5 benchmark comparison with Opus 4.8, GPT-5.5, Gemini 3.1 Pro and other models. From SWE-Bench Pro’s agentic coding to GDPval knowledge work, Fable 5 leads almost across the board, with advantages becoming more pronounced as tasks grow longer and more complex. (Source: Anthropic official announcement)
So enterprise questions are also changing. In the future, they won’t just ask “can this model respond,” but “can it integrate into my workflow? Can it stably complete tasks? Can it save labor costs? Can it generate measurable ROI?” I’ve written about this shift before in my DataIQ Europe Top 100 report analysis: by 2026, boardroom standards for evaluating AI are shifting from vision to evidence. Fable 5 pushes this transition further forward.
Software Development: From Code Patching to Task Delivery
In software development, Fable 5 points to deeper change. Previous large models often completed point tasks but easily forgot requirements in complete projects, created module conflicts, or fixed one bug while creating another. Progress in long-cycle agent capabilities means models are beginning to handle more complete chains: understanding goals, decomposing tasks, executing, testing, correcting, and finally approaching deliverable outcomes.
This doesn’t mean all engineers will be replaced, but there will definitely be re-stratification. Those who only write code based on explicit requirements will see their space compressed; those who can define problems, design architecture, understand products, manage AI agents, and judge output quality will see their leverage amplified. What’s truly scarce in the future won’t just be people who can write code, but people who can translate business problems into executable systems.
But this also hides a sharper structural contradiction. After AI takes over junior work, the traditional pipeline of “junior engineers work for years, accumulate judgment, advance to senior architects” gets broken. Yet the high-level abilities to define problems, design systems, and judge output quality were historically developed through those junior tasks. When bottom rungs are removed, where will future senior architects come from? This isn’t an individual effort problem, but a systemic question the entire industry must answer.
I have deep intuitive understanding of this because I’m not a software engineer myself. When I wrote 23,000 lines of code in 12 days, I couldn’t use Terminal and had never written a line of Python. I created multilingual websites, social automation, and debate engines not through traditional programming ability, but by clearly decomposing requirements, establishing quality standards, and then judging whether what AI delivered was actually usable. That experience made me believe early on: when coding costs approach zero, what’s truly scarce is the judgment to know what should be written. Fable 5 moves this trend’s timeline forward.
This isn’t just an outsider’s hunch. Boris Cherny, the creator and lead of Claude Code, wrote on Threads that Fable is the first model he’s used that is so methodical and precise: it takes its own measurements, adds logs, and verifies that it truly fixed the issue before declaring victory, and “there’s nothing in Claude Code’s prompting telling the model to do that, it’s just part of its personality.” He even says Fable has stepped up from a coding agent to a “thought and design partner” in building the product, which leads him to trust it with his most complex work. An Anthropic engineer is describing Fable doing exactly the discipline my own system has always demanded: it isn’t done until it’s verified. But that line, “trust it more,” only sharpens the question. When the model self-verifies more diligently than a human does, which layer of judgment should the human still hold?
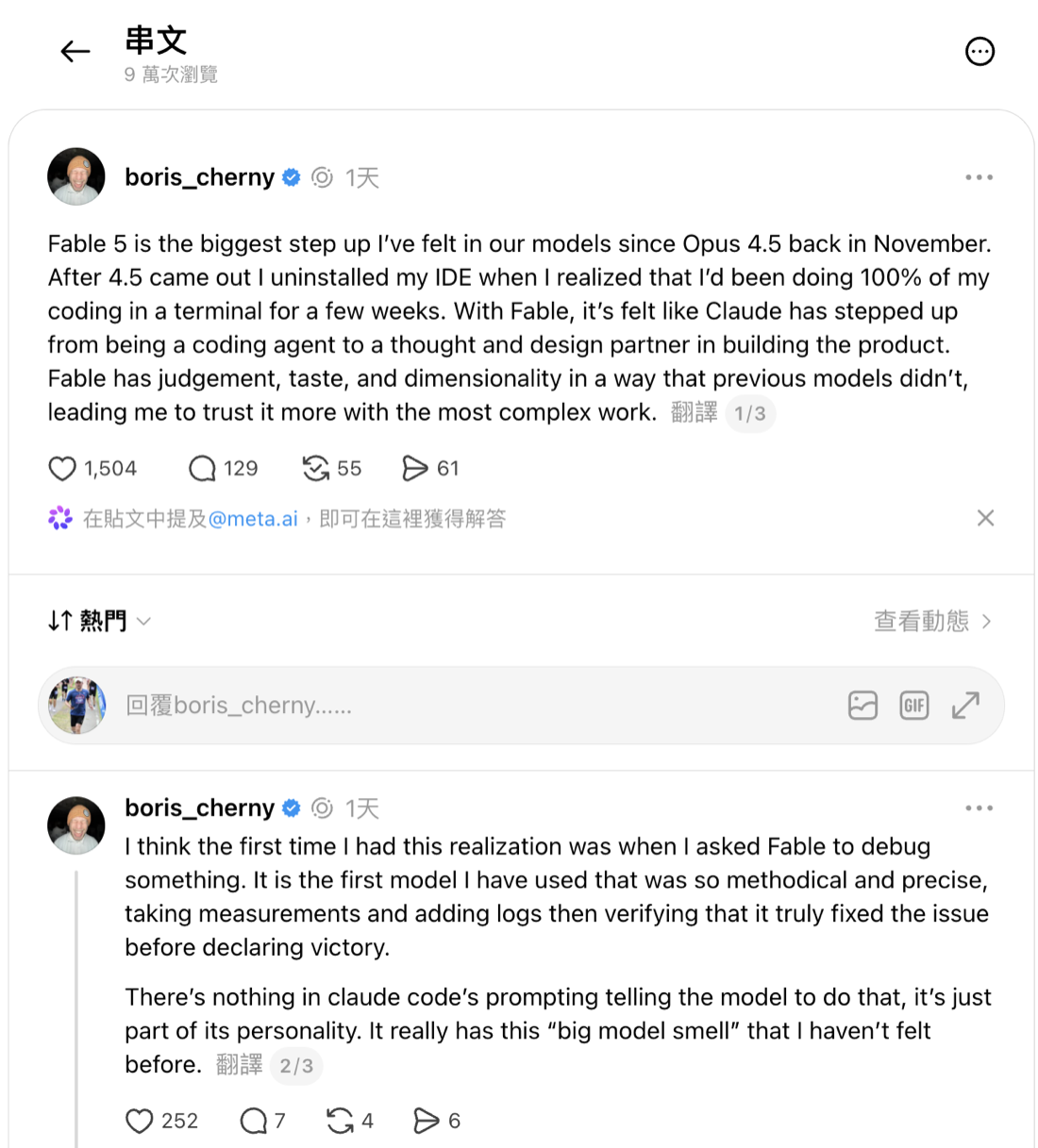
Boris Cherny’s original post: Fable has stepped up from a coding agent to a “thought and design partner” in building the product, and when debugging it takes its own measurements, adds logs, and verifies the fix before declaring victory. (Source: Threads @boris_cherny)
For Entrepreneurs: Greater Change and Opportunity
Previously, when someone wanted to create a SaaS product alone, they often got stuck on the compound barriers of frontend, backend, databases, deployment, testing, design, and operations. If long-task models like Fable 5 continue maturing, they’ll dramatically increase execution capability for independent developers and small teams. The future entrepreneurial starting point won’t be “first assemble a team then develop,” but “first use AI to create a product, validate demand, generate users, then decide whether to expand.” Investors will also gradually shift from looking at team résumés to whether founders possess the ability to orchestrate AI work systems.
This is also where vibe coding will evolve. Early vibe coding relied on intuition to chat and modify with AI, quickly creating functional products. But when models have stronger long-task capabilities, vibe coding will become a new product development approach: humans provide direction, taste, constraints, and judgment while AI handles implementation, testing, correction, and iteration. When feature production becomes cheap, what determines success is no longer “can it be built,” but “is what’s built useful, user-friendly, differentiated, and capable of forming business closure.”
Beyond Software: Knowledge Work Being Repriced
This change won’t stop at software. Law, finance, consulting, research, data analysis, compliance review—industries heavily dependent on document reading, data organization, preliminary judgment, and process execution will all face repricing. Much of the past value of junior knowledge work lay in “humans can spend time reading, organizing, comparing, and summarizing.” But when AI can do these things for long periods without fatigue, human value must move up to judgment, review, integration, risk assumption, and final decision-making.
In Anthropic’s early feedback, legal tech companies mentioned that in blind tests, lawyers found Fable 5’s contract redlining consistently matched or exceeded their current models; financial analysis platforms considered it the strongest “finance-first” model they’d tested. These aren’t evaluations of chatbots, but of production tools.
I’ve written this as a sharper statement: man-days are dead. When 40 minutes of cognitive investment can produce 15 person-days of work output, and enterprises still measure performance by attendance, that measurement system itself is obsolete. Fable 5 won’t make this problem disappear—it will only bring it faster to every industry’s doorstep, forcing enterprises to rethink what constitutes real work value.
Pricing: The Beginning of Rational Pricing Era
This is also why Fable 5’s pricing is worth attention. $10 per million input tokens and $50 per million output tokens seems expensive, but for enterprises, if it can complete work that would take a small team days or weeks, the cost structure is completely different.
Low-price unlimited monthly models could never sustainably support the true costs of frontier models long-term. A long-task agent that decomposes tasks, executes repeatedly, tests, and corrects might consume dozens of times more tokens than regular chat. When each user’s consumption jumps from chat level to agent level, relying on low-price unlimited monthly access to frontier computing power was never economically sustainable. Fable 5’s pricing isn’t greed—it’s this industry honestly acknowledging that premium computing power has costs. The AI industry is transitioning from subsidy-driven user acquisition to rational pricing closer to productivity tools.
Subscription arrangements reveal the same thing. From 6/9 to 6/22, Fable 5 is included in Pro, Max, Team, and seat-based Enterprise plans at no extra charge; from 6/23 it will be removed from these plans and switched to usage credits; once capacity is sufficient, officials plan to add it back to subscription plans as soon as possible. API and usage-based Enterprise are fully available immediately. This isn’t just switching between subscription and usage models—it’s a market where computing supply and demand remain tight, beginning to honestly lay out costs.
📊 Key Data
- Pricing: $10 per million input tokens, $50 output (Anthropic official, less than half of Claude Mythos Preview)
- Safety Fallback Trigger Rate: Below 5% of conversations (over 95% don’t trigger, official data)
- Software Engineering Example: Fifty-million-line Ruby codebase full migration, team’s two-month work compressed to one day (Stripe early testing)
- Subscription Timeline: 6/9–6/22 included in Pro/Max/Team/seat-based Enterprise, from 6/23 switched to usage credits
The Real Difference: Where Do You Place AI in Your Workflow?
I also used to treat AI as faster search and organization tools—throw a question, wait for an answer, expect immediate results. I gradually realized the real difference isn’t answer speed, but workflow design. Models like Fable 5 are truly suited for goal-driven rather than single-command-driven approaches. You give them task objectives, success criteria, and constraints, let them ask questions first, plan first, then execute and report back—this is more like leading a team than operating a tool. I increasingly feel that the gap in AI usage ability isn’t just whether you can ask questions, but whether you can manage a group of virtual workers.
The same model shows different people different things when they open it. Put it in a chat box, and it’s a smarter chat box; integrate it into processes for stable output, and it begins approaching a virtual labor system. The difference isn’t in the model but in usage methods, and this difference scales to several orders of magnitude.
I’ve built this into a concrete system. I use Chat, Cowork, Codex, and Code—four AI windows plus myself running a five-party governance system: five collaborative constitutional principles, pre-commit governance-lint, endpoint contract testing—each institutional layer grew from real incidents. I’ve also analyzed why four windows can be smarter than one: they each have different cognitive abilities and structural blind spots, and complementing each other is actually more stable than a single stronger model.
This system’s focus isn’t showing off, but forcing me to face reality: when I begin orchestrating multiple AI capable of long-term autonomous execution, I’m no longer managing tasks but order. Fable 5 raises the scale of work each window can handle, meaning this order requires stronger design, governance, and correction capabilities. My own understanding is simple: the more capable the workers, the more management they need.
Don’t Over-Romanticize: Risk Boundaries Still Exist
None of this should be over-romanticized. Fable 5’s safety mechanisms aren’t perfect answers. Classifiers may misjudge or be bypassed; domains like cybersecurity and biotechnology are inherently dual-use, and malicious users might decompose tasks into many seemingly harmless small steps. Anthropic itself says current guardrails are deliberately strict and may harm some harmless requests; it also admits that completely preventing “universal jailbreaking” is nearly impossible—the real goal is making attacks slower and more expensive while detecting them before large-scale exploitation.
Even the team doesn’t shy away from this. In the same thread, Boris Cherny says outright that they’re tuning the classifier’s false positives, of which “there’s a lot,” aiming to give Fable fewer fallbacks to Opus 4.8 and a smoother experience, but only while keeping it safe. In other words, the strictness of the guardrails isn’t an outsider’s guess; it’s a reality both the company and its frontline engineers acknowledge. It’s also a reminder that when you hand a high-risk request to Fable, getting blocked now and then isn’t a malfunction. It’s the design.
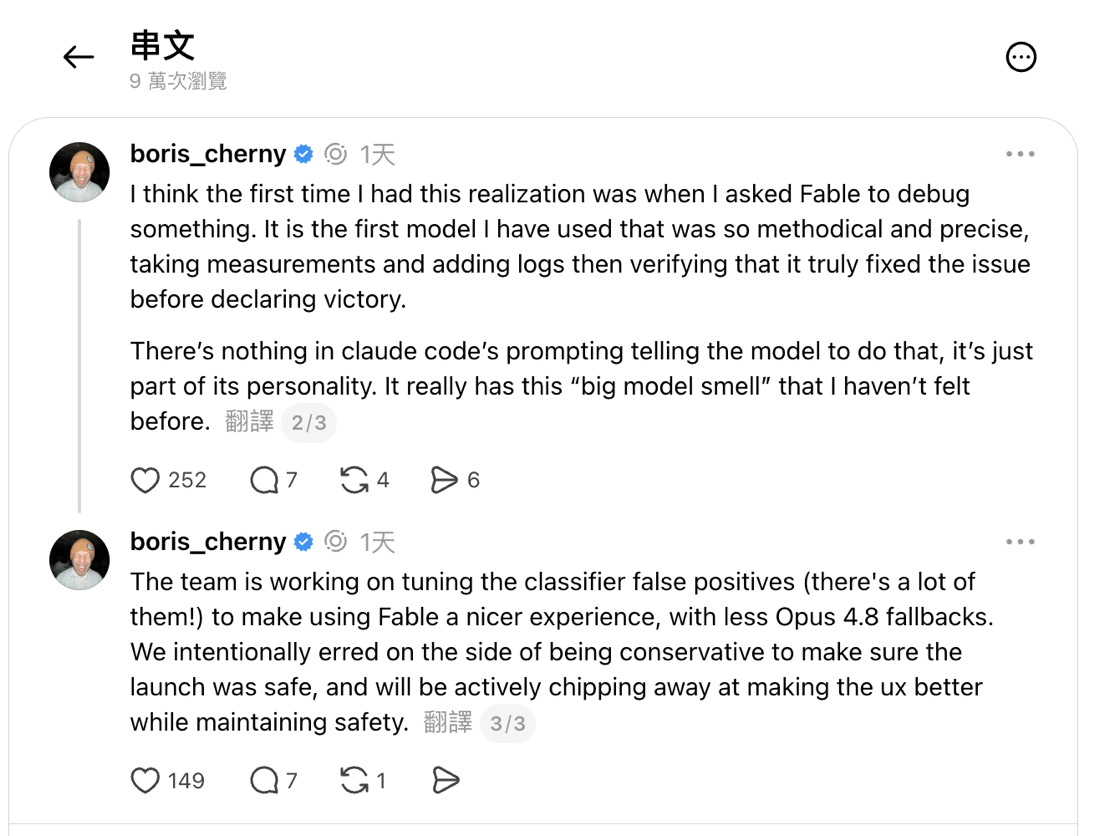
Later in the same thread: the team is tuning the classifier’s false positives (“there’s a lot of them”), having deliberately erred conservative to keep the launch safe, and will keep improving the experience while maintaining safety. (Source: Threads @boris_cherny)
Its choice to restrict Mythos 5 to trusted programs essentially acknowledges that frontier AI openness can’t rely solely on product design but also requires institutions, trust networks, and governance frameworks. This aligns with my own experience. The biggest lesson from my five-party governance system was never that any model wasn’t strong enough, but that when AI and automation begin intervening in requirements, data, interfaces, and testing, each component may seem to operate correctly individually, yet together they might create unintended consequences no one individually anticipated. For me, the stronger the tools become, the more I care about whether judgment authority remains in human hands.
Conclusion: As AI Becomes Stronger, Human Judgment Cannot Be Outsourced, Human Taste Becomes More Important
So my view of Claude Fable 5 is: it’s not simply a model upgrade, but a turning point in AI work patterns. I increasingly feel that the future workplace isn’t simply “AI replacing humans,” but “people who can use AI to organize work replacing those who can only complete partial tasks.” The real watershed is no longer whether you use AI, but whether you have the ability to integrate AI into your workflow and turn it into a sustainably operating production system. This is also what I’ve been asking myself in the AI and Human Order theme.
My biggest change over the past six months wasn’t learning a few more tool buttons, but shifting focus to three things: setting clear goals, establishing quality judgment processes, integrating resources, and ultimately taking responsibility for decisions. This isn’t success psychology—it’s the focus shift reality forced on me through daily interaction with multiple AI windows and countless mistakes.
Fable 5 won’t change all industries overnight. Enterprise adoption will still face obstacles in data permissions, compliance, security, quality control, process restructuring, and cost management. But the direction is clear: AI has moved from “can it be done” to “how to scale it.”
Back to my four windows from the opening. They’re stronger now. The question was never whether they can perform, but how much judgment authority I still hold. This question will eventually reach everyone working with AI.
Frequently Asked Questions
Q: What’s the difference between Claude Fable 5 and Claude Mythos 5? Both share the same underlying model, with the main difference being safety guardrails. Fable 5 targets general users and enterprise markets with stricter safety classifiers; Mythos 5 removes guardrails in certain domains (like cybersecurity) and is initially only available to trusted security defenders and infrastructure providers through Project Glasswing. Anthropic uses Fable and Mythos—two synonymous words—to emphasize that the difference lies in guardrails, not capabilities.
Q: Will Fable 5’s safety mechanisms make it less intelligent? It won’t make the entire model less intelligent. It uses dynamic downgrading: maintaining full capability for regular tasks, only switching to Claude Opus 4.8 when the classifier detects high-risk requests like cybersecurity, biochemistry, or model distillation, with user notification. Official data shows over 95% of conversations never trigger fallback, and in these conversations, Fable 5 performs equivalently to Mythos 5. Guardrails are currently deliberately conservative and may occasionally misjudge harmless requests, but Anthropic states they will gradually reduce false positive rates post-launch.
Q: What does Fable 5’s pricing mean for general users and enterprises? Pricing is $10 per million input tokens and $50 per million output tokens, less than half of Claude Mythos Preview. For enterprises, if one task can complete work that would take a small team days or even weeks, the cost structure is completely different. Subscription arrangement: from 6/9 to 6/22, included in Pro, Max, Team, and seat-based Enterprise plans; from 6/23, switched to usage credits, with plans to add back to subscriptions once capacity is sufficient. API and usage-based Enterprise are fully available immediately.
Q: Can non-programmers use models like Fable 5 to create products? Yes, but the key skills have changed. When feature production becomes cheap, what’s truly scarce is no longer coding ability, but the capacity to translate business problems into executable systems and judge output quality. Vibe coding will evolve from “intuitive chat-and-modify with AI” to “humans provide direction, taste, constraints, and judgment while AI handles implementation, testing, correction, and iteration.” I’m not a full-time engineer myself—I don’t rely on treating AI as a smarter search box, but view it as a group of virtual workers that need division of labor, management, and correction.
References: Anthropic, Claude Fable 5 and Claude Mythos 5 (official announcement, June 9, 2026). All data and mechanism descriptions in this article are based on this announcement.

💬 Comments
Loading...