
TL;DR — Claude Fable 5 的意義,不只是模型又升級了一次,而是讓已經在運轉的 AI 工作流,開始進入長任務代理階段。Fable 5 和 Mythos 5 能比過去任何 Claude 模型自主執行更長時間的任務,而且任務越長、越複雜,Fable 5 領先其他模型的幅度就越明顯。它透過動態安全分流,讓一般任務保留完整能力,只在高風險情境下交由 Opus 4.8 處理。真正的分水嶺,已不再是有沒有使用 AI,而是能不能把 AI 接進自己的工作流,形成一套持續運轉、可被管理的生產力系統。
上週發一篇文章時,我同時開著四個 AI 視窗。一個在改前端,一個在跑翻譯,一個在同步治理紀錄,另一個在跟我討論這段文字該怎麼寫。我很清楚,我不是在「使用」AI,而是在「調度」一群能力各異的 AI 工作者。那一刻它們在我眼裡,已經比較像一種新的生命體,而不是工具:會自己動、自己長,也會彼此踩線。發完文章後我才更明確意識到,我管理的早就不是一個個零散任務,而是一整套會自己運轉、偶爾會彼此衝突的工作秩序。
2026 年 6 月 9 日(今天),Anthropic 發布 Claude Fable 5。表面看,只是一個新模型版本;但對我這種每天調度 AI、把 AI 接進研究、寫作、判斷與決策流程的人來說,它是一個訊號:原本仍需人工拆解、轉接、校正與補位的 AI 工作流,可以再次優化進入下一階段。Fable 5 讓原本已經在運轉的 AI 工作系統,變得可更長程運轉、更穩定,也更接近真正的自主協作。
Fable 5 真正的看點,為什麼是安全分流而不是能力?
這次值得注意的,不只是模型能力又提升了多少,而是 Anthropic 用兩層架構來治理前沿模型能力。一層是面向一般使用者與企業市場的 Claude Fable 5;另一層是能力限制較少、但只開放給受信任資安防禦者與關鍵基礎設施的 Claude Mythos 5。兩者共享同一個底層模型,差別只在護欄。官方甚至特別解釋了命名:Fable 來自拉丁文 fabula,意思是「被講述之事」,跟希臘文的 Mythos 同源。用兩個近義字命名同一個底層模型,其實是在把一件事講清楚:差別主要在安全護欄,不在底層能力。
這個分層設計,反映的是前沿 AI 已經不能只用一般產品邏輯來理解。當模型能力進入資安、生物化學、軟體工程與長任務自主執行的層級,它就不再只是一般消費性科技產品,而是具備現實世界影響力的生產工具。同一種能力,可以幫防禦者修補漏洞,也可能降低攻擊者的門檻;可以加速藥物與生命科學研究,也可能觸及高風險的雙重用途問題。
所以 Fable 5 最值得觀察的,是它的安全分流機制。過去很多模型一旦為了安全變保守,常常連一般使用者都覺得能力縮水。Fable 5 走的是另一條路:平常任務盡量保留完整能力,只有當系統偵測到資安、生物化學或模型蒸餾這類高風險請求時,才改由較保守的 Claude Opus 4.8 回應,而且會通知使用者。官方數據是超過 95% 的會話完全不會觸發這種回退,在那些會話裡,Fable 5 的表現等同於 Mythos 5。
這代表 AI 公司正在試一種新的治理邏輯:不是把整個模型變笨,而是在高風險情境裡做動態降級。我自己很能理解這套設計背後的取捨。對一個靠 AI 工作的人來說,最怕的不是模型有底線,而是模型為了守底線變得處處綁手綁腳。如果降級真的能被限縮在不到 5% 的會話裡,意思是多數日常工作仍然可以踩在最強的那一檔能力上,而不是為了少數高風險情境,犧牲整體使用體驗。
為什麼說這是 AI 產業成熟化的開始?
這背後其實是 AI 產業成熟化的起點。當模型只是聊天工具,大家比的是回答自然不自然、速度快不快、價格便不便宜。但當模型開始能執行長任務、理解大型程式碼庫、整理複雜文件、參與金融分析、協助法律審閱,競爭的標準就換了。
這個標準會換到什麼程度?Anthropic 公布的早期測試裡,Stripe 用 Fable 5 在一個五千萬行的 Ruby 程式碼庫做了一次全庫遷移,原本一整個團隊手做要兩個多月的工作,模型一天完成。這已經不是「補幾行 code」的等級,而是開始承接一整段工作鏈條。
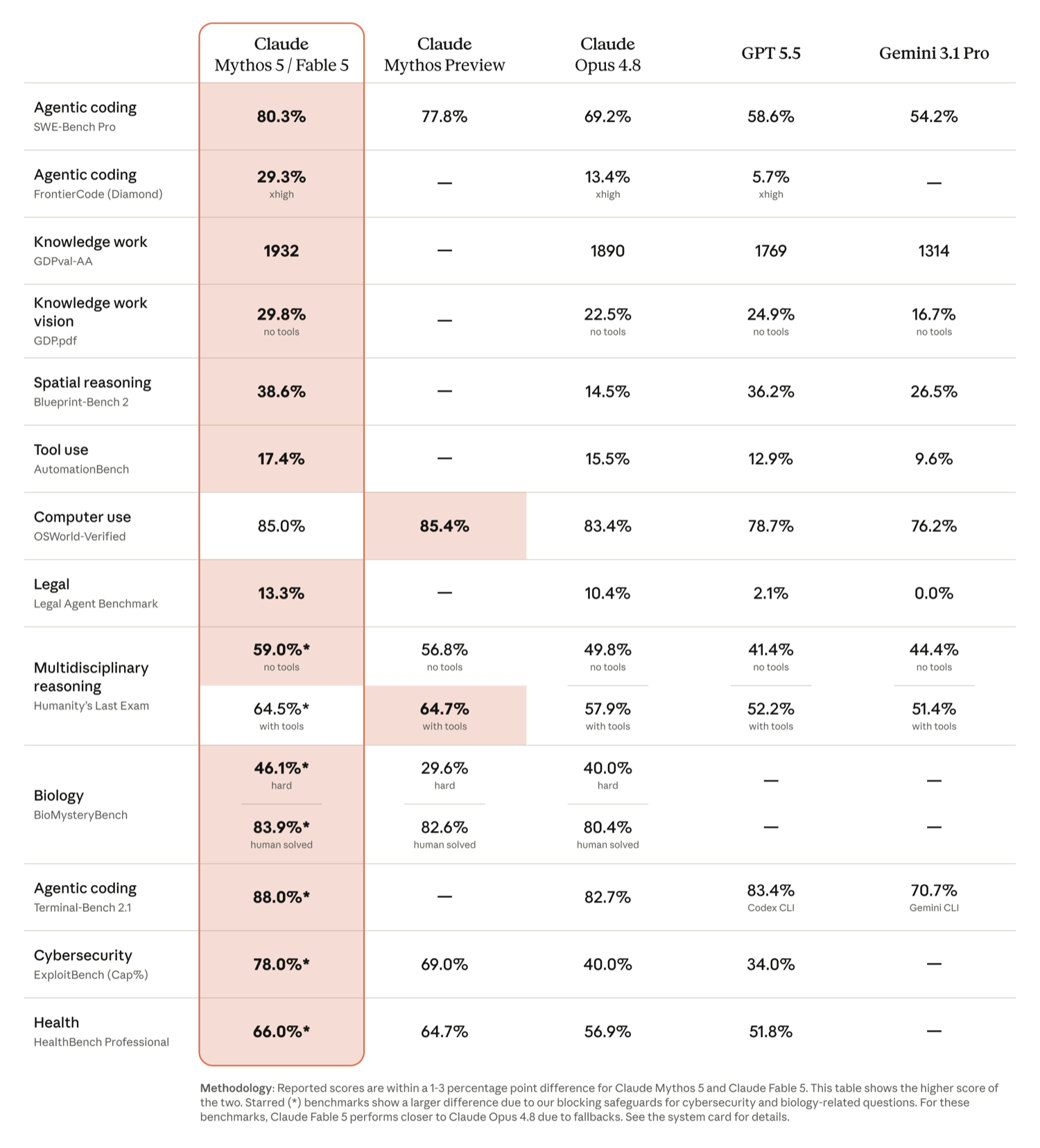
Claude Fable 5/Mythos 5 與 Opus 4.8、GPT-5.5、Gemini 3.1 Pro 等模型的 benchmark 對照。從 SWE-Bench Pro 的 agentic coding 到 GDPval 知識工作,Fable 5 幾乎全面領先,而且任務越長、越複雜,領先幅度越明顯。(來源:Anthropic 官方公告)
於是企業問的問題也變了。未來他們不會只問「這個模型會不會回答」,而會問「它能不能接進我的工作流?能不能穩定完成任務?能不能省下人力成本?能不能跑出可衡量的 ROI?」這套提問,我在 DataIQ 歐洲百大報告的導讀 裡寫過:2026 年董事會檢驗 AI 的標準,正在從願景轉向證據。Fable 5 則把這個轉向再往前推了一步。
軟體開發:從補程式碼走向任務交付
在軟體開發上,Fable 5 指向的是一個更深的變化。過去的大模型常常可以完成單點任務,卻容易在完整專案裡遺忘需求、產生模組衝突,或修一個 bug 又製造另一個 bug。長週期代理能力的進步,代表模型開始能承接更完整的鏈條:理解目標、拆解任務、執行、測試、修正,最後接近可交付成果。
這不代表所有工程師都會被取代,但一定會重新分層。只會根據明確需求寫程式的人,空間會被壓縮;能定義問題、設計架構、理解產品、管理 AI agent、判斷成果品質的人,槓桿會被放大。未來真正稀缺的,不只是會寫 code 的人,而是能把商業問題翻譯成可執行系統的人。
但這裡也藏著一個更尖銳的結構性矛盾。初級工作被 AI 接走之後,原本「初級工程師做幾年、累積判斷力、升上資深架構師」這條養成管線就斷了。可是能定義問題、設計系統、判斷成果品質的高階能力,過去往往正是從這些初級任務裡磨出來的。當底層階梯被抽掉,未來的高級架構師要從哪裡長出來,這不是個人努力的問題,是整個產業要回答的系統問題。
我對這件事有很深的體感,因為我自己並不是軟體工程師。我 12 天寫了 23,000 行程式碼 的時候,不會用 Terminal,也沒寫過一行 Python。我做出多語系網站、社群自動化與辯論引擎,靠的不是傳統程式能力,而是把需求拆清楚、把品質標準訂明白,然後判斷 AI 交出來的東西到底能不能用。那次經驗讓我相信:當寫程式的成本趨近於零,稀缺的是知道該寫什麼的判斷。Fable 5 把這個趨勢的時間表往前推了。
這不只是我一個外行人的體感。Boris Cherny,Claude Code 的創始人和負責人,在 Threads 上寫,Fable 是他用過第一個如此「有條理而精準」的模型:會自己量測、加 log,驗證真的修好了才宣布成功,而且「Claude Code 的提示詞裡沒有任何一句叫它這樣做,這純粹是它性格的一部分」。他甚至說 Fable 讓 Claude 從寫程式的代理,升格成一起打造產品的「思考與設計夥伴」,因此他更敢把最複雜的工作交給它。一個 Anthropic 自己的工程師,描述 Fable 正在做的,恰好就是我這套系統一直在要求的紀律:驗完才算完。但他那句「更敢交出去」,把開發者的生存處境逼得更緊。當模型連自我驗證做得比人勤與精確,人能守住的,是哪一層的判斷?
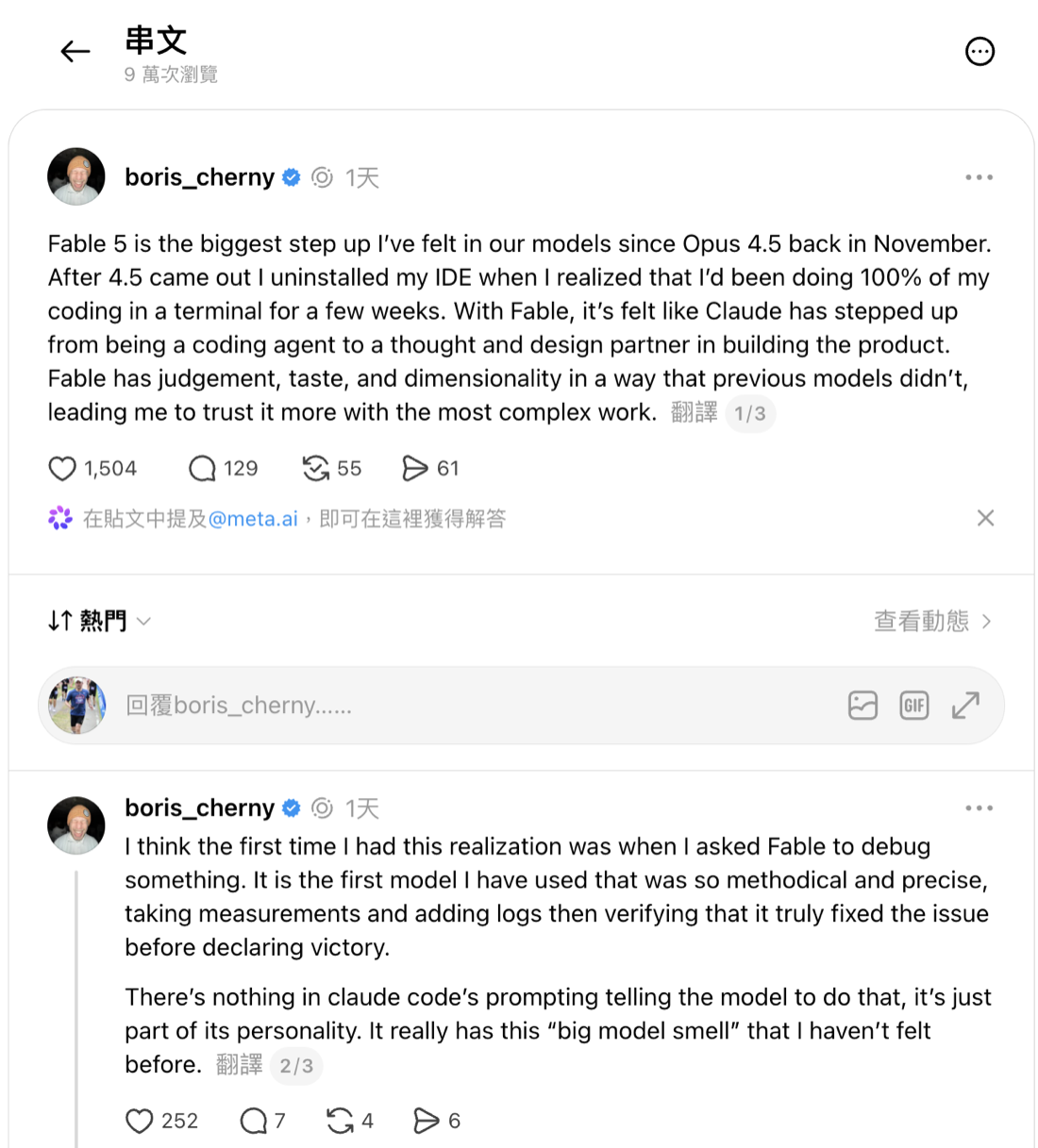
Boris Cherny 的原貼:Fable 從寫程式代理升格為一起打造產品的「思考與設計夥伴」,debug 時會自己量測、加 log、驗證真的修好了才宣布成功。(來源:Threads @boris_cherny)
對創業者來說,這是更大的改變與機遇
過去一個人想做 SaaS 產品,往往卡在前端、後端、資料庫、部署、測試、設計、維運這一整排複合門檻。Fable 5 這類長任務模型如果持續成熟,會讓獨立開發者和小團隊的執行力大幅提高。未來創業的起點,不再是「先找齊團隊再開發」,而是「先用 AI 做出產品、驗證需求、跑出用戶,再決定是否擴張」。投資人看的,也會逐漸從團隊履歷,移到創辦人是否具備調度 AI 工作系統的能力。
這也是 vibe coding 會演化的地方。早期的 vibe coding 是靠直覺跟 AI 邊聊邊改,快速做出可以運作的產品。但當模型有了更強的長任務能力,vibe coding 會變成一種新的產品開發方式:人提供方向、品味、約束與判斷,AI 負責實作、測試、修正、迭代。當功能生產變便宜,決定勝負的就不再是「能不能做出來」,而是「做出來的東西有沒有用、好不好用、有沒有差異、能不能形成商業閉環」。
不只軟體業:知識工作正在被重新定價
這個變化不會只停在軟體業。法律、金融、顧問、研究、資料分析、合規審查,這些高度依賴文件閱讀、資料整理、初步判斷與流程執行的行業,都會面臨重新定價。大量初級知識工作過去的價值,在於「人可以花時間讀、整理、比對、歸納」。但當 AI 可以長時間、不疲倦地做這些事,人的價值就必須上移到判斷、審核、整合、風險承擔與最終決策。
Anthropic 公布的早期回饋裡,有法律科技公司提到,旗下律師在盲測中發現 Fable 5 的合約紅線標註,每次都追平或勝過他們現用的模型;也有金融分析平台認為,它是目前測過最強的「金融優先」模型。這些都不是對聊天機器人的評語,而是對生產工具的評語。
我把這件事寫成過一個更尖銳的說法:人天已死。當 40 分鐘的認知投入能產出 15 人天的工作量,企業還在用出席率衡量績效,那套度量衡本身就過時了。Fable 5 不會讓這個問題消失,只會讓它更快攤到每個產業面前,逼企業重新思考什麼才是真正的工作價值。
定價:理性定價期的開始
這也是為什麼 Fable 5 的定價值得關注。每百萬輸入 token 10 美元、每百萬輸出 token 50 美元,看起來貴,但對企業來說,如果它能完成原本一個小團隊數天甚至數週的工作,成本結構就完全不同。
低價包月吃到飽的模式,本來就很難長期支撐前沿模型的真實成本。一個會自己拆任務、反覆執行、測試與修正的長任務代理,跑一輪消耗的 token,可能是一般聊天的好幾十倍。當每個使用者的消耗從聊天等級跳到代理等級,靠低價包月無限使用前沿算力,從成本結構上看,本來就不可能長期成立。Fable 5 的定價不是貪婪,是這個產業誠實地承認:頂級算力是有成本的。AI 產業正在從補貼搶用戶的圈地階段,進入更接近生產力工具的理性定價階段。
訂閱方案的安排也透露了同一件事。6/9 到 6/22,Fable 5 包含在 Pro、Max、Team 與席次制 Enterprise 方案裡不另外收費;6/23 起會從這些方案移除,之後使用要動用 usage credits;等容量足夠,官方計畫盡快把它加回訂閱方案。API 與用量制 Enterprise 則是即日起完整開放。這不只是訂閱制與用量制之間的切換,而是一個算力供需仍然緊張的市場,開始誠實把成本攤開來講。
📊 關鍵數據
- 定價:每百萬輸入 token 10 美元、輸出 50 美元(Anthropic 官方,不到 Claude Mythos Preview 一半)
- 安全回退觸發率:低於 5% 的會話(超過 95% 不觸發,官方數據)
- 軟體工程實例:五千萬行 Ruby 程式碼庫全庫遷移,團隊兩個多月的工作壓縮到一天(Stripe 早期測試)
- 訂閱時程:6/9–6/22 含於 Pro/Max/Team/席次制 Enterprise,6/23 起改用 usage credits
真正的差別:你把 AI 放在工作流的哪一層?
我早期也曾把 AI 當成更快的搜尋與整理工具,丟一句、等一句、要它立刻給答案。後來才慢慢意識到,真正的差別不在答案速度,而在工作流設計。Fable 5 這類模型,真正適合的是目標驅動,而不是單點指令驅動。你給它任務目標、成功標準與限制條件,讓它先提問、先規劃,再執行、再回報;這比較像是在帶一個團隊,而不是操作一個工具。我愈來愈覺得,AI 使用能力的差距,不只是會不會問問題,而是能不能管理一組虛擬工作者。
同一個模型,不同人打開它看到的東西不一樣。把它放在聊天框裡,它就是一個更聰明的聊天框;把它接進流程、穩定產出,它就開始接近一套虛擬勞動力系統。差別不在模型,在使用方式,而這個差別會放大到好幾個量級。
我把這套東西做成了一個具體的系統。我用 Chat、Cowork、Codex、Code 四個 AI 視窗加上我自己,跑一套五方議事的治理工程:協作憲法五條、pre-commit 的 governance-lint、端點契約測試,每一層制度都是從真實事故裡長出來的。我也分析過 為什麼四個視窗會比一個聰明:它們各有不同的認知能力和結構性盲點,互相補位反而比單一更強的模型更穩。
這套系統的重點不在炫技,而在於它逼我面對事實:當我開始調度多個能長時間自主執行的 AI,我管理的已經不是任務,而是秩序。Fable 5 把每一個視窗能承接的工作量級往上抬,也意味著這套秩序需要更強的設計、治理與校正能力。我自己的體會很簡單:工作者能力越強,越需要管理。
不要過度浪漫化:風險邊界仍然在
這一切不該被過度浪漫化。Fable 5 的安全機制不是完美答案。分類器可能誤判,也可能被繞過;資安與生物科技這些領域本身就是雙重用途,惡意使用者也可能把任務拆成許多看似無害的小步驟。Anthropic 自己也說,目前護欄刻意調得偏嚴,可能會誤傷一些無害請求;它也坦言,要完全杜絕「通用越獄」幾乎不可能,真正的目標是讓攻擊變得更慢、更貴,並在被大規模利用前先被發現。
這點連團隊內部也不避諱。Boris Cherny 在同一串貼文裡直說,團隊正在調整分類器的誤判,「數量不少」,目標是讓 Fable 少一點 fallback 到 Opus 4.8、用起來更順,但前提是維持安全。換句話說,護欄偏嚴不是外界的猜測,是官方與第一線工程師都承認的現狀。這也提醒我們,把高風險請求交給 Fable 時,偶爾被擋下來不是故障,是設計。
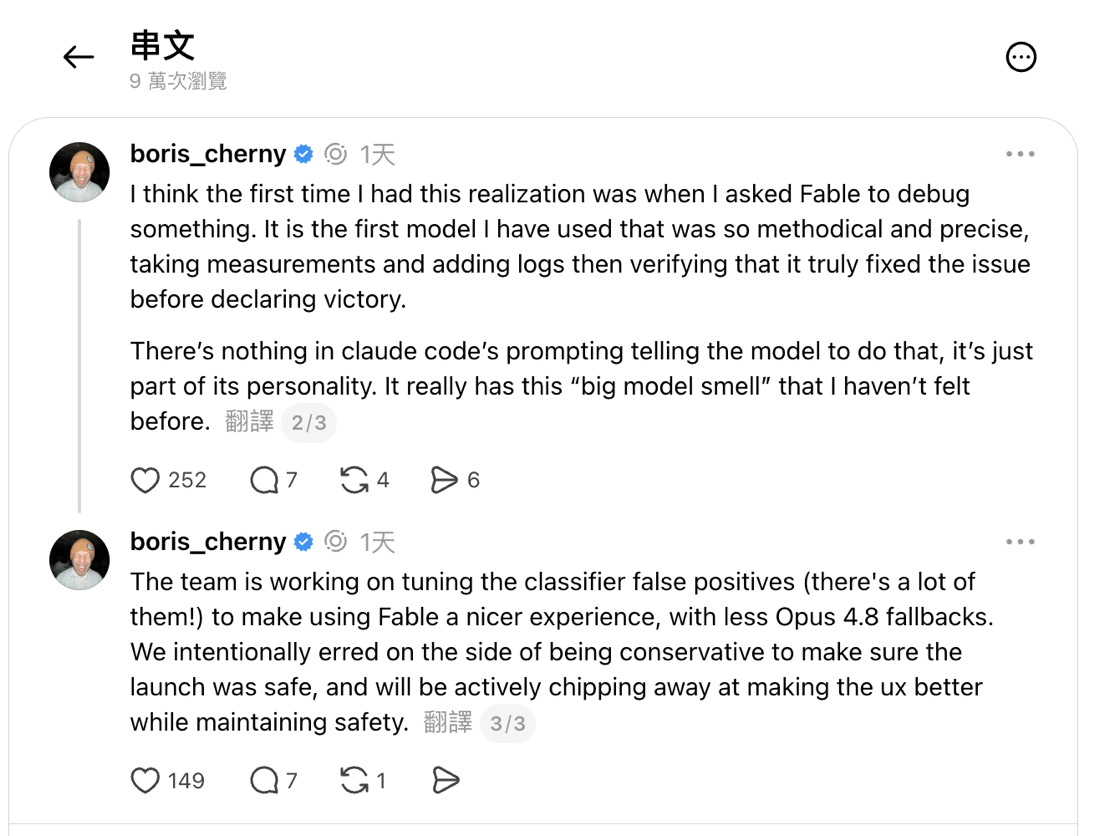
同一串貼文後段:團隊正在調整 classifier 的誤判(「數量不少」),刻意保守是為了確保發布安全,之後會在維持安全的前提下逐步改善體驗。(來源:Threads @boris_cherny)
它選擇把 Mythos 5 限制在受信任計畫裡,某種程度上就是承認:前沿 AI 的開放,不可能只靠產品設計,還需要制度、信任網絡與治理框架。這跟我自己的體會一致。我那套五方議事系統最大的教訓,從來不是哪個模型不夠強,而是 當 AI 與自動化開始介入需求、資料、畫面與測試,每個元件看似都在正確運作,最後卻可能一起製造出一個沒有人單獨預期到的反作用力。對我來說,工具能力越強,我反而越在意:判斷權有沒有留在人手上。
結語:當 AI 變強,人的判斷權更不能外包,人的品味更重要
所以我對 Claude Fable 5 的看法是:它不是單純的模型升級,而是 AI 工作型態的一個轉折點。我愈來愈覺得,未來職場不是簡單的「AI 取代人類」,而是「會用 AI 組織工作的人,取代只會完成局部任務的人」。真正的分水嶺,不再是有沒有使用 AI,而是有沒有能力把 AI 接進自己的工作流,變成一套可持續運轉的生產系統。這也是 智能與秩序 這個主題裡,我一直在追問自己的事。
我這半年最大的轉變,不是多學了幾個工具按鈕,而是把力氣移到三件事上:把目標定清楚、把品質判準流程建立起來、把資源整合起來,最後扛下決策。這不是成功學,是我每天跟多 AI 視窗打交道,踩過無數坑,被現實一次次逼出來的重心轉移。
Fable 5 不會在一夜之間改變所有行業。企業導入仍然會卡在資料權限、合規、安全、品質控管、流程重整與成本管理。但方向已經很清楚:AI 已經從「能不能做」走進「如何規模化地做」。
回到我開頭那四個視窗。它們現在更強了。問題從來不是它們會不會做,而是我還握著多少判斷權。這個問題,遲早會輪到每一個用 AI 工作的人。
常見問題
Q:Claude Fable 5 和 Claude Mythos 5 差在哪? 兩者共享同一個底層模型,主要差別在安全護欄。Fable 5 面向一般使用者與企業市場,加上較嚴格的安全分類器;Mythos 5 把部分領域(例如資安)的護欄解除,初期只透過 Project Glasswing 開放給受信任的資安防禦者與基礎設施供應商。Anthropic 用 Fable 與 Mythos 這兩個近義字命名,正是要凸顯差別在護欄,不在能力。
Q:Fable 5 的安全機制會不會讓它變笨? 不會把整個模型變笨。它採取動態降級:平常任務保留完整能力,只有當分類器偵測到資安、生物化學或模型蒸餾這類高風險請求時,才改由 Claude Opus 4.8 接手回應,並會通知使用者。官方數據是超過 95% 的會話完全不觸發回退,在這些會話裡 Fable 5 的表現等同於 Mythos 5。護欄目前刻意調得保守,偶爾會誤判無害請求,Anthropic 表示會在發布後逐步收斂誤判率。
Q:Fable 5 的定價,對一般使用者和企業意味著什麼? 定價是每百萬輸入 token 10 美元、輸出 50 美元,不到 Claude Mythos Preview 的一半。對企業來說,如果一次任務能完成原本一個小團隊數天甚至數週的工作,成本結構就完全不同。訂閱安排是:6/9 到 6/22 包含在 Pro、Max、Team 與席次制 Enterprise 方案,6/23 起改用 usage credits,待容量足夠後官方計畫盡快加回訂閱。API 與用量制 Enterprise 即日起完整開放。
Q:不會寫程式的人,能用 Fable 5 這類模型做出產品嗎? 可以,但關鍵能力換了。當功能生產變便宜,真正稀缺的不再是會寫 code,而是能把商業問題翻譯成可執行系統、並判斷成果品質的能力。Vibe coding 會從「靠直覺跟 AI 邊聊邊改」演化成「人提供方向、品味、約束與判斷,AI 負責實作、測試、修正、迭代」。我自己不是全職工程師,靠的不是把 AI 當成更聰明的搜尋框,而是把它視為一組需要被分工、管理與校正的虛擬工作者。
參考來源:Anthropic, Claude Fable 5 and Claude Mythos 5(官方公告,2026-06-09)。本文數據與機制描述均以此公告為準。

💬 留言討論
載入中...