
70,267。
程式跑完的那一刻,螢幕上跳出這個數字。我盯著它看了幾秒,我在手機裡,按下了七萬多次快門,而且可以記錄的清清楚楚。每一次,都是某個瞬間裡,我覺得眼前的世界值得留下來的時刻。
一場意外的數位考古
今年一月開始用 Claude 的 Cowork 功能,本來只是想讓 AI 幫我處理電腦裡那些拖延已久的瑣事:檔案歸類、訂閱整合、各種技術債。沒想到協作效率遠超預期,過去因為忙碌而無限期擱置的事情,像積木一樣被快速拼起來。照進度排到這週,輪到累積多年的照片。
七萬多張。跟 AI 協作寫了一個 Python 腳本,讀取每張照片的 Metadata,分析年份分佈、萃取地理座標,最後輸出成一份 JSON 報告。過程不太順利,沒設定好工作程序,電腦當了好幾次。但跑完之後看著那份報告,感覺不像在整理檔案,更像做了一次生命軌跡的開挖。
時間曲線的長相
整理出來的年份分佈圖,畫出了一條我沒預料到的曲線。
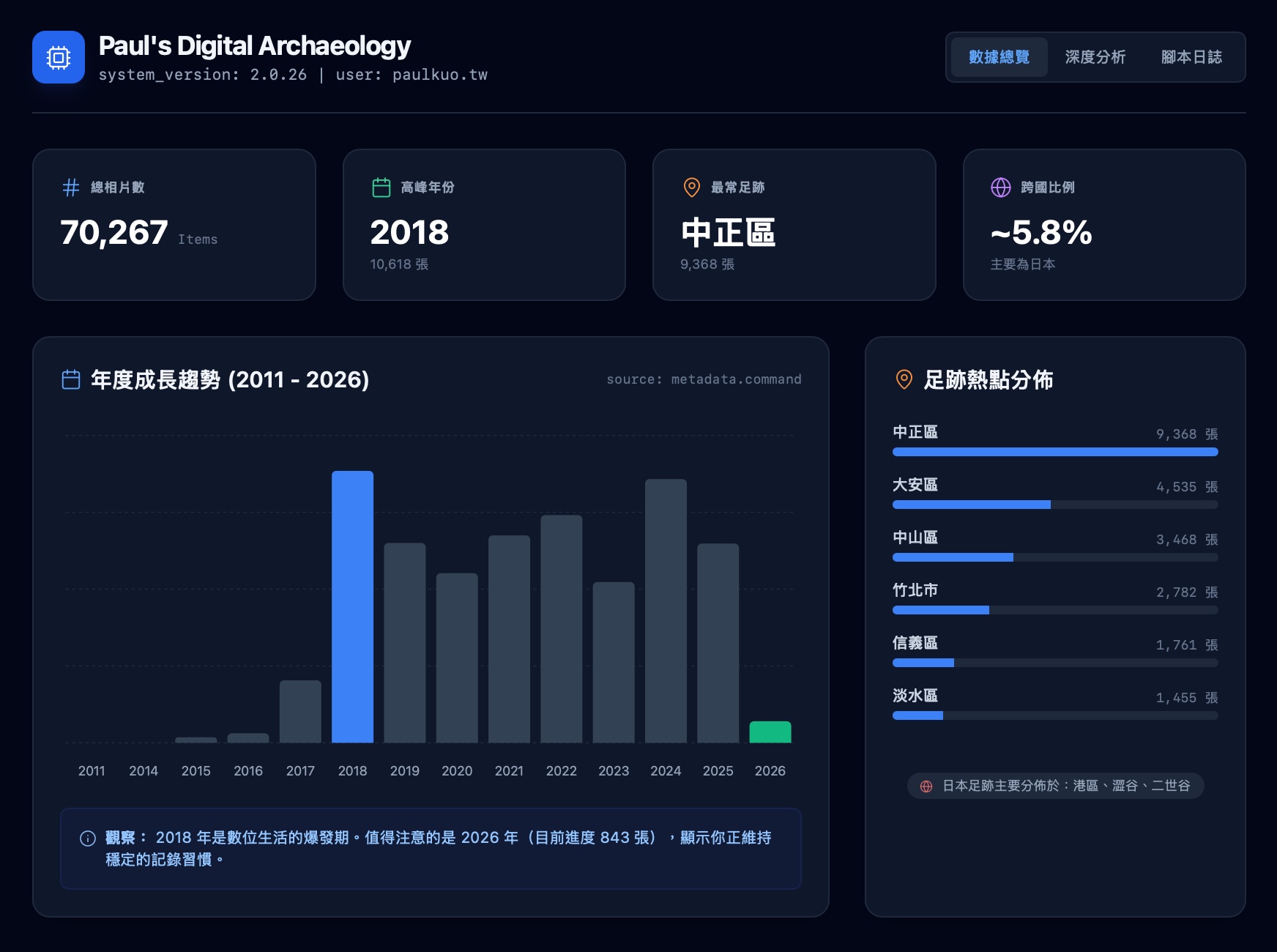
2015、2016 年還算平緩,照片數量穩定。但到了 2018 年,數據突然爆發式躍升。回頭想,那正是我人生節奏加速的起點:新的際遇、事業轉向、跨國移動最頻繁的時期,城市在換、場景在轉、工作在變,旅行與相遇在不同的座標上交錯。
有人說,五十歲以後生活會逐漸收斂:活動減少、移動距離縮短、人生趨於穩定。我一度也這樣以為。但把資料攤開,發現自己的活動密度不減反增。這不是雞湯式的「永保青春」,而是數據告訴我的事實。我沒有在收斂。
這讓我想到一件事:我們對自己人生的敘事是流動的。不是因為故意扭曲,而是因為記憶本身就不是一個可靠的資料庫。
Metadata 的誠實
記憶會騙人。細節會被時間磨平,故事被當下的情緒重新詮釋。你記得某次旅行「好像是夏天」,但 Metadata 告訴你那是十一月。你覺得某段時期「過得很平淡」,但照片密度說那其實是你最活躍的一年。
神學裡有個概念我一直很在意:人對自身處境的理解,往往受制於當下的感受,而不是事實。奧古斯丁在《懺悔錄》裡花了大量篇幅處理記憶與時間的關係:用現代話說,他的意思是:記憶不是過去的複製品,而是現在對過去的重新建構。一千六百年後,Metadata 用另一種方式印證了這件事:影像參數裡的時間戳和GPS座標不會被情緒改寫。某條異國的街道、某場會面、某段旅程、某張特殊照片,它們安靜地停留在檔案的參數裡,比我們的腦袋誠實得多。
這就是我覺得整理照片這件事有意思的地方。表面上是在歸檔影像,實際上是在把模糊的記憶轉化為可檢索的資料。為自己的時間建索引。
從回憶到查詢
我們這一代”人”的記憶,已經可以不只靠腦細胞保存了。可同時存在於手機相簿、雲端硬碟、社群貼文、健康追蹤App。有精準的時間與地點、有城市之間的移動軌跡、有人與人之間的社交圖譜,也有按下快門那一刻的心情。在某些情況下,它還能跟生理數據結合,例如,如果我要比對,我的Fitbit資料可以告訴我,某張照片拍攝當下的心率是多少。
當這些碎片被整理、被參數化、被結構化,它就不再只是「回憶」了。它變成可以被搜尋、被交叉比對、被重新組織的東西。你跟自己過去的關係,從「我記得⋯⋯」變成了「讓我查一下⋯⋯」。
我在建造 paulkuo.tw 的過程中體會到一件事:當人把自己的經驗、觀點、軌跡系統性地輸出,就不再只是活過,而是把活過的痕跡變成了一種可被索引的存在。照片整理是同一件事的另一個面向。
留給未來的索引
看著影像被轉換為資料結構的時候,我在想一個問題:十年、二十年後,當我回頭看「過去」,我能找到什麼?
不完全是感傷式的提問,而是一個很實際的問題:如果未來的我需要重拾某個片段,現在的我有沒有留下足夠的索引?時間會繼續走,記憶會繼續模糊,但如果資料結構還在,那些曾經覺得值得留下的瞬間,至少不會完全消失在時間裡(如果我的肉體朽壞,我的記憶 Agent 還能心意更新且變化嗎?我還不知道)。
七萬多個時間節點。每一個背後都是某個秒鐘裡的眷念或交流的餘溫。它們不會記得我當時在想什麼,但它們記得我在哪裡、什麼時候、面對著什麼方向、思念什麼、在意什麼。
也許這就夠了。剩下的,就交給未來的我自己去填。

💬 留言討論
載入中...