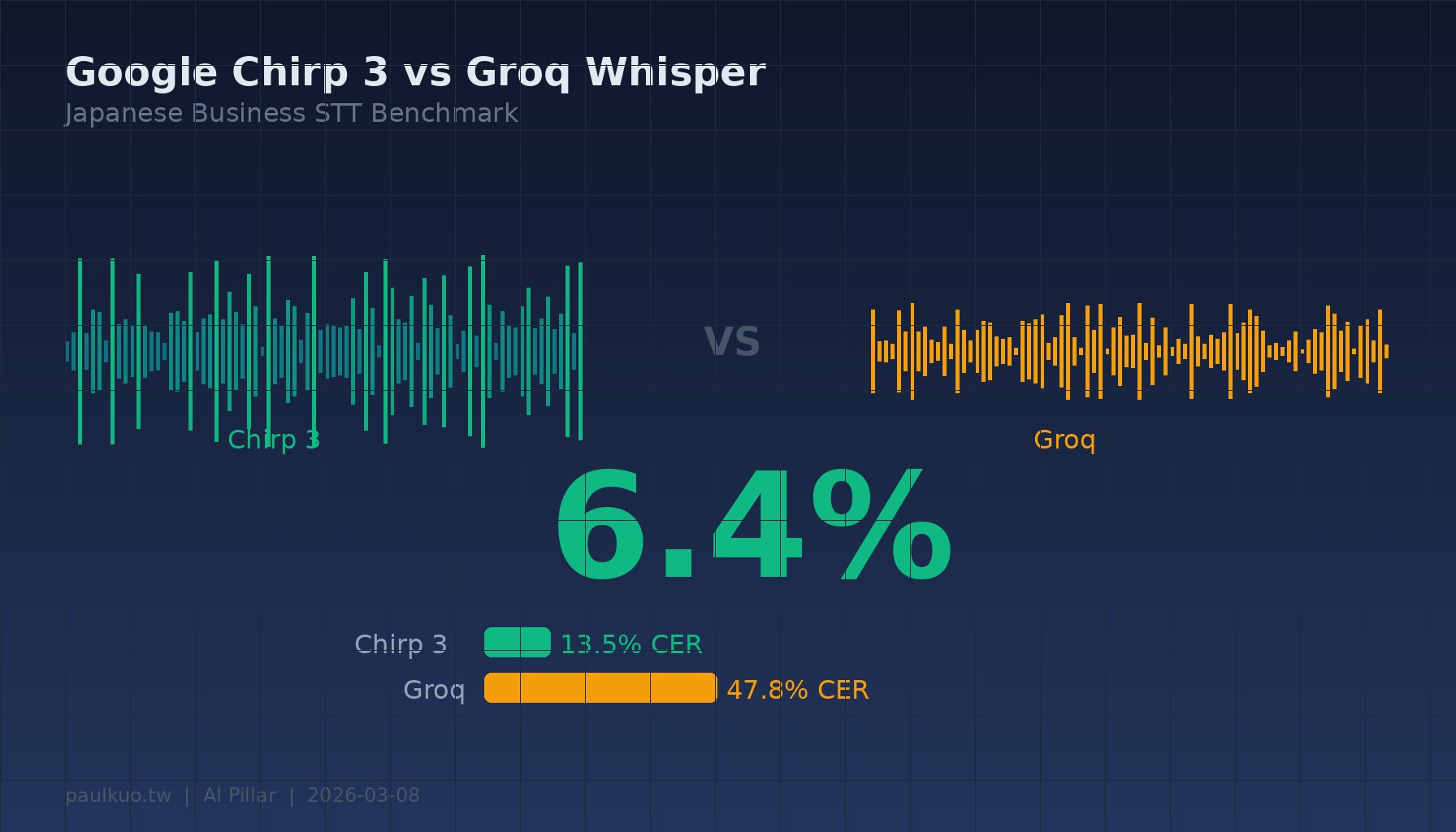
6.4%。
這是 Google Chirp 3 在辨識一段 TSMC 半導體技術解說影片時的字元錯誤率。同一段音檔丟給 Groq Whisper,錯誤率是 36.5%。一個幾乎逐字正確,另一個每三個字就錯一個。
這不是什麼精心設計的實驗室條件,就是 YouTube 上隨便找的日文解說影片,前三分鐘,切下來跑兩個引擎。結果的差距,大到讓我重新思考一件事:我們對「免費 AI 工具」的信任,到底建立在什麼基礎上?
為什麼我要做這個測試
這套「即時會議記錄|阿哥拉廣場」工具,算是成為超級個體實踐的延伸,透過與 AI 協作,一個人等於是一支部隊。技術上不複雜:麥克風收音、語音辨識、即時翻譯、字幕顯示。但實際用在日文商務會議上,會有一個致命的問題:辨識結果會干擾理解。
「取引先」變成亂碼,「発注書」被吃掉一半,「ご指導のほど」被聽成完全不相干的詞。這些不是偶爾的錯誤:是架構設計的系統性問題。而這些詞,恰恰是商務場景中最關鍵的術語。
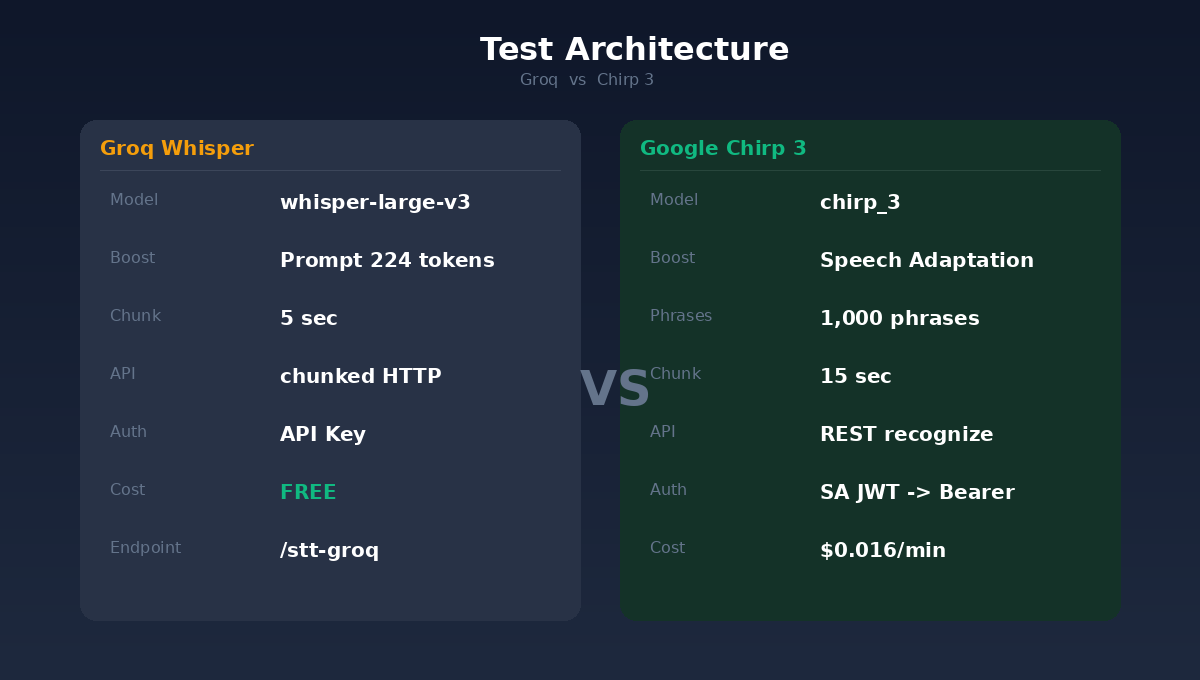
原本用的是 Groq 提供的免費 Whisper 模型。速度快、不花錢,日常對話勉強能用,聽聽嗯嗯啊啊,讓人開心的影片沒問題。但若對方是日本客戶,你正在翻譯一場關於設廠時程和品質異常的會議:「勉強能用」就不夠了。
所以我想繼續優化,試著達標更高的 benchmark 檢視,用數據來回答:Chirp 3 到底好多少?值不值得花那個錢?
四個場景,一面倒的結果
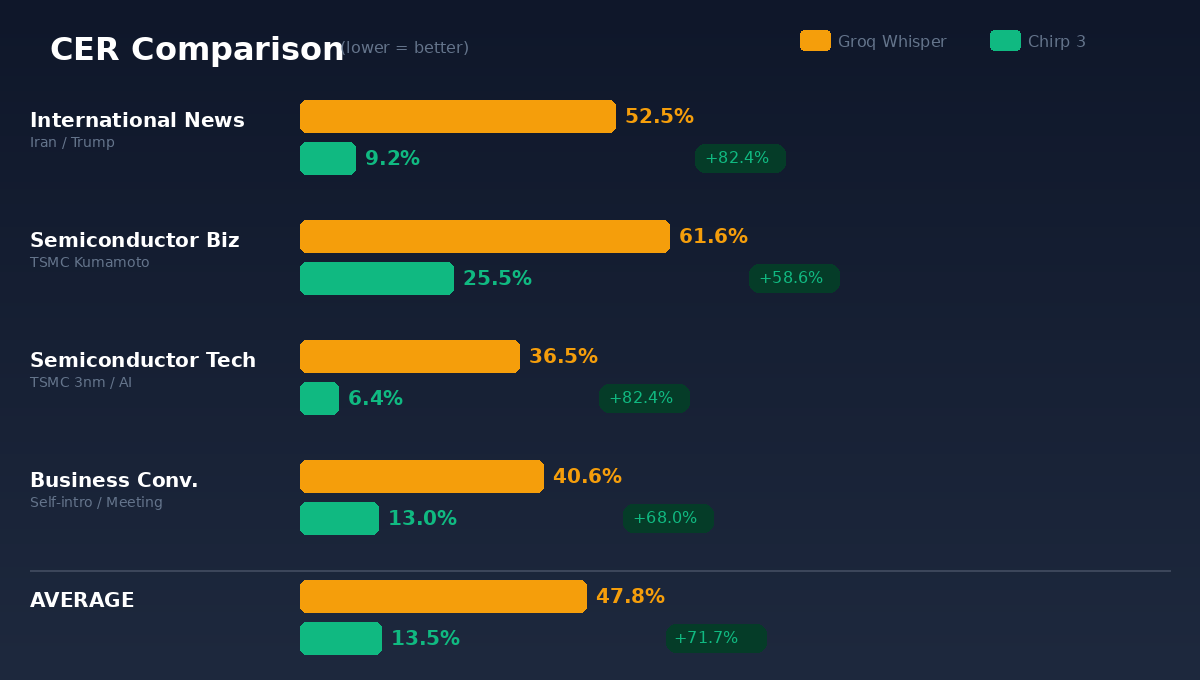
我挑了四段完全不同類型的日文影片,每段取前三分鐘,分別送進兩個引擎,以 YouTube 自動生成字幕為基準計算 CER(字元錯誤率,Character Error Rate:簡單說就是辨識結果跟正確答案之間的差異比例,越低越好)。
結果:
國際新聞(PIVOT 節目:川普攻擊伊朗解說):Groq 52.5%、Chirp 3 9.2%,改善 82.4%。
半導體商務(TSMC 熊本工廠戰略分析):Groq 61.6%、Chirp 3 25.5%,改善 58.6%。
半導體技術(TSMC 3nm、AI、地緣政治):Groq 36.5%、Chirp 3 6.4%,改善 82.4%。
商務會話(自我介紹、會議準備):Groq 40.6%、Chirp 3 13.0%,改善 68.0%。
平均下來:Groq 的 CER 是 47.8%,Chirp 3 是 13.5%。精準度提升 71.7%。
四個場景,Chirp 3 全勝。沒有例外。
數字背後的關鍵:不只是模型好,是「知道該聽什麼」
Chirp 3 贏這麼多,不只是因為模型本身更強。關鍵在一個功能:Speech Adaptation。
這是 Google Cloud Speech-to-Text 提供的術語引導機制。你可以預先餵給模型最多 5,000 個「短語」(phrases),告訴它:這場會議可能會出現這些詞,請優先辨識。
我讓系統放了約 1,000 個日文商務術語進去:從「取引先」「発注書」「見積書」到「応急措置」「前年比」「稟議」。效果立竿見影:這些詞的命中率幾乎是 100%。
反觀 Groq Whisper 的 prompt 機制,上限只有 224 tokens,大約塞得下 40 個術語。而且 Whisper 有個惡名昭彰的問題:靜音段會「幻覺」,把 prompt 裡的內容直接吐出來當辨識結果。
還有一個容易被忽略的差異:切片長度。Groq 用 5 秒一段,Chirp 3 用 15 秒。5 秒的語境太短,模型經常聽到一半就斷了,上下文不足導致誤判。15 秒則給了模型足夠的語境去做判斷。
這三個因素疊加:更強的基礎模型、1,000 個術語引導、更長的語境窗口:造成了三倍的精準度差距。
一場會議不到一美元
Chirp 3 不是免費的。計費方式是 $0.016 美元/分鐘,以秒為最小計費單位。
算一下:一場一小時的日文商務會議,Chirp 3 的成本是 $0.96 美元。不到一美元。
如果你每個月開 20 場日文會議,月費大約 $19 美元,折合新台幣 624 元。
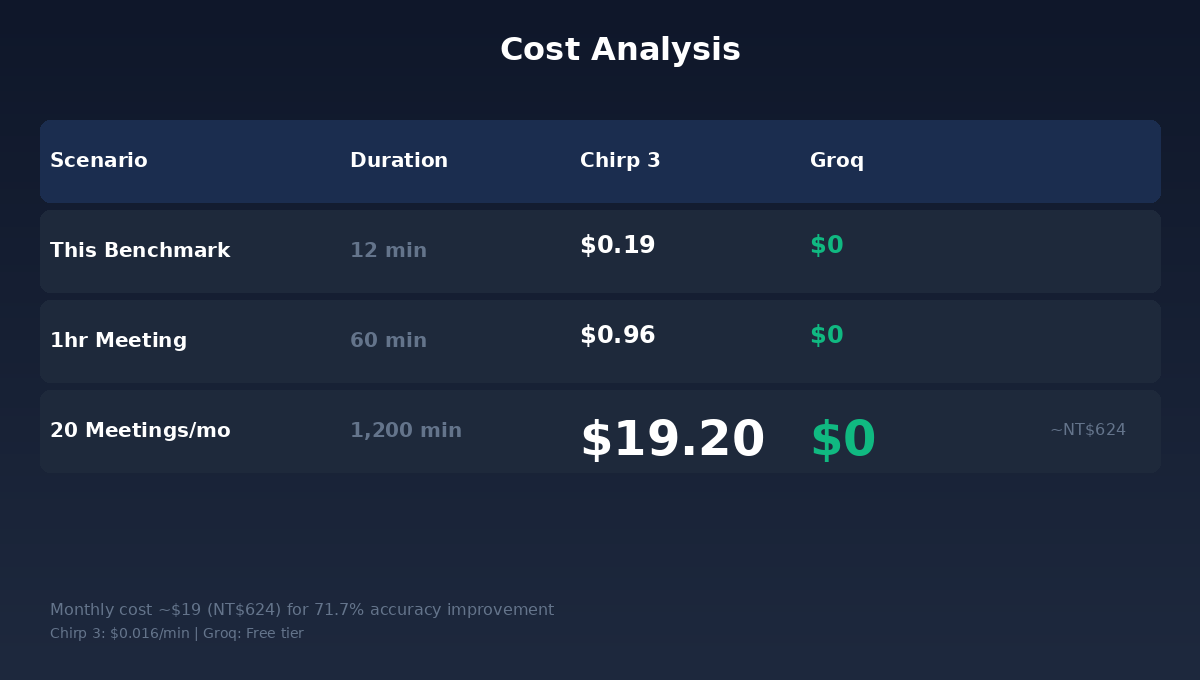
624 元。換取的是:日本夥伴說的每一個專業術語,都能正確記錄下來;我們會議紀錄可以不再需要事後花一小時人工修正;翻譯品質從「看得懂大意」提升到「可以直接當逐字稿用」。
創業這些年,我理解到:溝通的成本,從來不在工具上:在誤解上。 一次聽錯「納期」導致的交期延誤,代價遠超過一年的 Chirp 3 費用。
我的翻譯工具現在怎麼用它
最後補充一下技術面。目前這一版翻譯工具採用「多路路由」架構,意思是,我根據來源語言和使用模式,自動切換不同的辨識引擎:
中文走 Qwen(阿里的中文 ASR 模型,WebSocket 串流),英文走 Groq Whisper(免費、速度快),日文一般模式也走 Groq,但日文商務模式自動切換到 Google Chirp 3,同時把使用者的術語表詞彙一起送進 Speech Adaptation。其他語言則走 Deepgram Nova-3。
這個設計的邏輯很簡單:不是所有場景都需要最高精準度,但商務場景不能妥協。 Groq 免費、速度快,適合日常對話和非正式場合。Chirp 3 貴一點、慢一點(15 秒才回傳一次),但在精準度上是另一個等級。

我按「商務模式」按鈕(管理者才有的技能),背後的路由就自動切換:不需要理解技術細節,只需要知道:開了這個按鈕,你的日文會議紀錄會從「大概對」變成「幾乎完全對」。
精準度是信任的基礎
回到最初的問題:免費 STT 夠用嗎?
如果只是想把 YouTube 影片的日文大意聽個七七八八,知道大意那OK。但如果你在一場跨國會議裡,對方正在用敬語委婉地表達不滿,而翻譯工具把「ご立腹」聽成了「ボディポップ」(沒有開玩笑,這是真實案例):那就完全不夠。
語音辨識的精準度不是一個抽象的技術指標。它是溝通鏈條中最脆弱的一環。辨識錯了,翻譯就錯了;翻譯錯了,決策就偏了。在商務場景裡,這條鏈是用信任串起來的。
6.4% 的錯誤率,意味著每 100 個字只錯 6 個。47.8% 的錯誤率,意味著將近一半的內容不可靠。
我寧願多花一點 Token 費用,也希望確保與夥伴之間的交流能維持更好的品質。不過我也理解,對很多朋友來說,日語素材其實不一定需要那麼精準。人生已經夠不容易了,需要輕鬆一點的時刻,就讓自己輕鬆一點。
術語表
- CER(Character Error Rate):字元錯誤率。衡量辨識結果與正確答案的差異,計算方式是 Levenshtein 編輯距離除以正確答案的字數。越低越好,0% 代表完美。
- STT(Speech-to-Text):語音轉文字技術。
- Ground Truth:用於比對的「正確答案」。本測試使用 YouTube 自動生成的日文字幕。
- Speech Adaptation:Google Cloud STT 的功能,允許預先提供最多 5,000 個短語引導模型辨識特定詞彙。
- Levenshtein Distance:編輯距離。將一個字串轉換成另一個字串所需的最少操作次數(插入、刪除、替換)。
- Prompt:Whisper 模型的提示文字(上限 224 tokens),用於引導辨識方向。功能類似 Speech Adaptation,但容量小得多。
- RPM(Requests Per Minute):每分鐘請求數,API 的速率限制。Groq 免費方案為 20 RPM。

💬 留言討論
載入中...