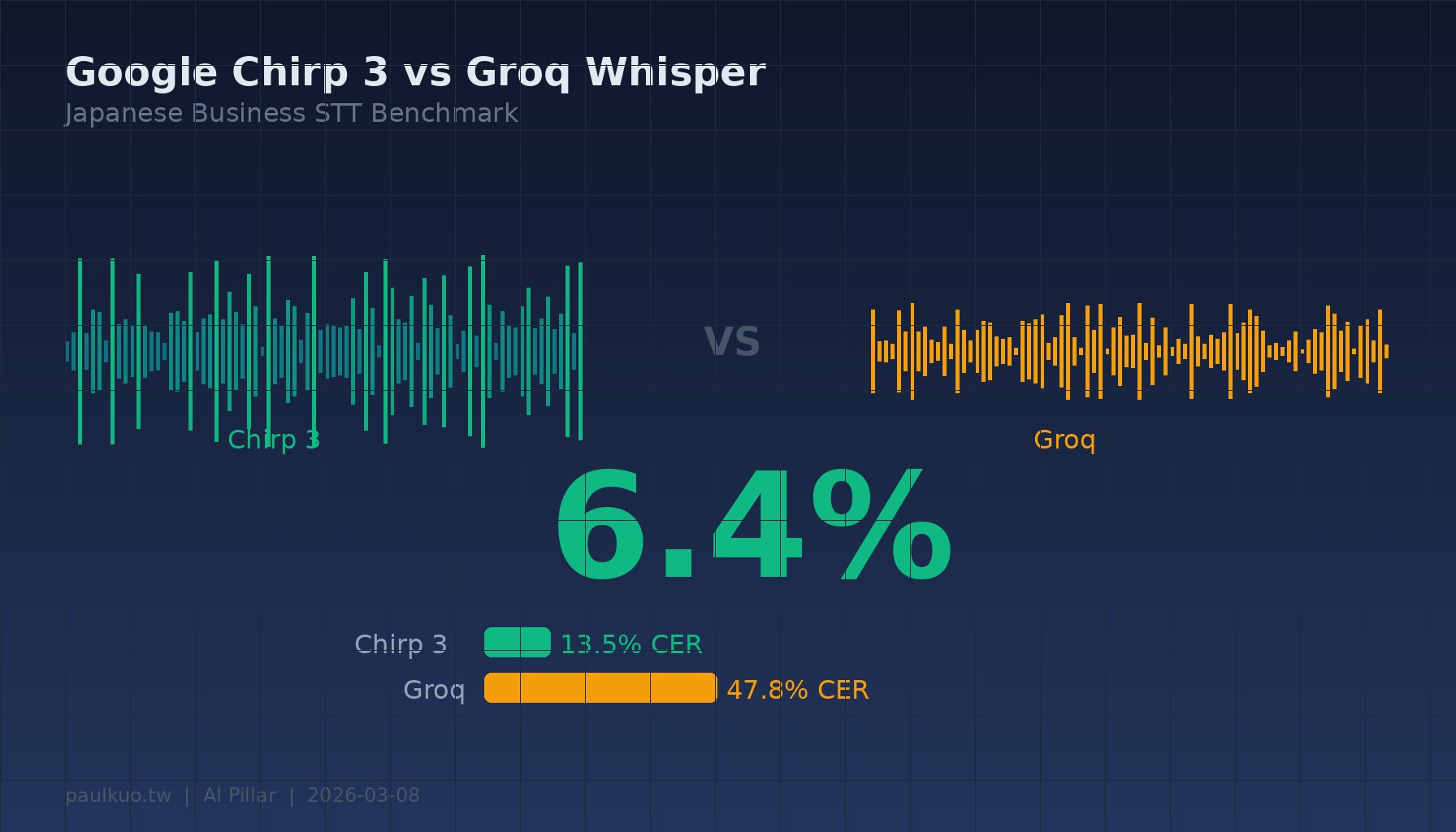
6.4%。
これはGoogle Chirp 3がTSMC半導体技術解説動画の一部を認識した際の文字エラー率である。同じ音声ファイルをGroq Whisperに投げると、エラー率は36.5%。一つはほぼ逐字正確、もう一つは3文字に1つが間違い。
これは精密に設計された実験室条件ではなく、YouTubeで適当に見つけた日本語解説動画の最初の3分間を切り出し、2つのエンジンで処理しただけだ。結果の差は、私に一つのことを再考させるほど大きかった:「無料AIツール」への信頼は、一体何を基盤としているのか?
なぜこのテストを行ったのか
最近、リアルタイム会議翻訳ツールを開発している—スーパー個体実践の延長として、一人でAIを使って本来チーム全体が必要な仕事を完成させることだ。技術的には複雑ではない—マイク収音、音声認識、リアルタイム翻訳、字幕表示。しかし実際に日本語商用会議で使用すると、致命的な問題がある:認識結果が理解を妨害する。
「取引先」が文字化け、「発注書」が半分欠ける、「ご指導のほど」が全く関係ない語彙として聞き取られる。これは偶発的なエラーではない—システム設計の構造的問題である。そしてこれらの語彙こそが、商用シーンで最も重要な専門用語なのだ。
元々はGroqが提供する無料Whisperモデルを使用していた。速度が速く、費用がかからず、日常会話なら何とか使える。うんうんああ、と相槌を打つような楽しい動画には問題ない。しかし相手が日本のクライアントで、建設スケジュールと品質異常に関する会議を翻訳している場合—「何とか使える」では不十分である。
そこで最適化を続け、より高いベンチマーク検証の達成を試み、データで答えたい:Chirp 3は実際どれほど優れているのか?その費用に見合う価値があるのか?
4つのシーン、一方的な結果
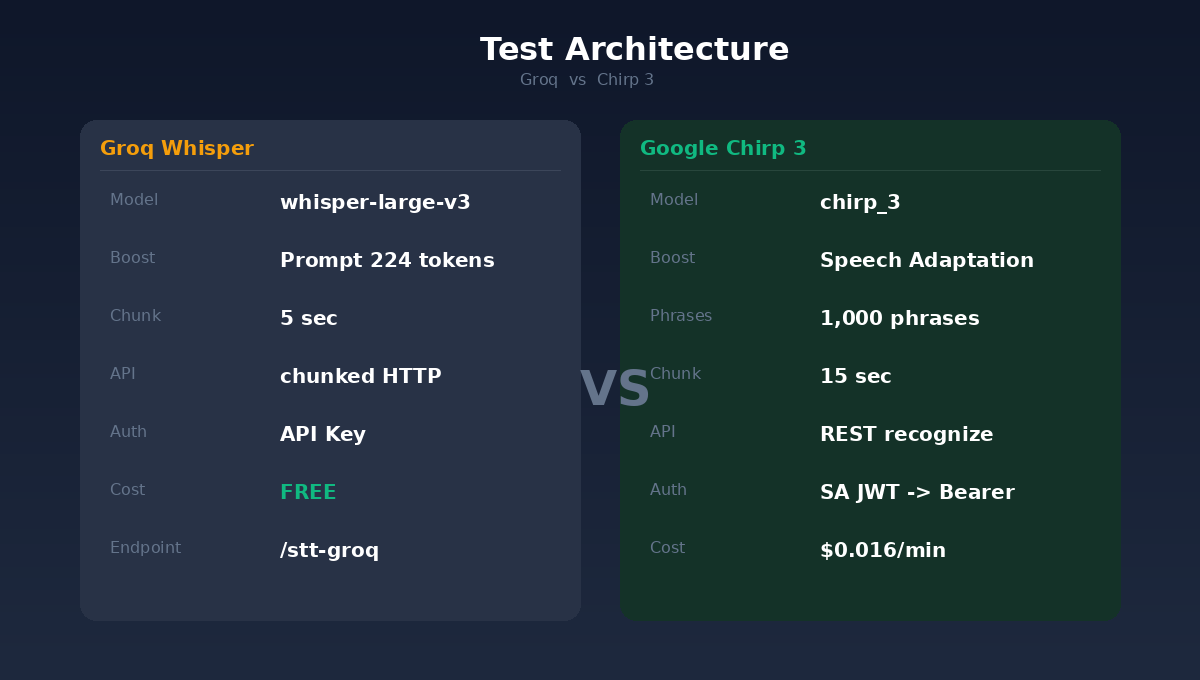
4つの完全に異なるタイプの日本語動画を選び、各々最初の3分間を取り出し、2つのエンジンに送った。YouTubeの自動生成字幕を基準にCER(文字エラー率、Character Error Rate—簡単に言えば認識結果と正解との差異比率で、低いほど良い)を計算した。
結果:
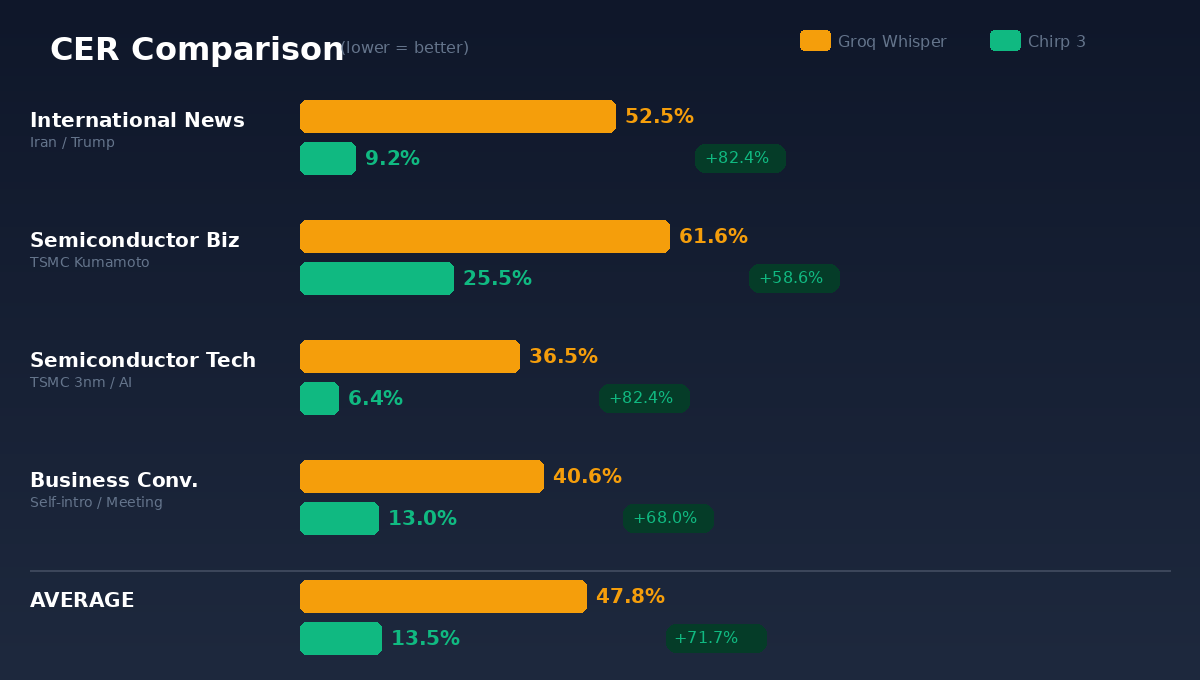
国際ニュース(PIVOT番組:トランプのイラン攻撃解説)—Groq 52.5%、Chirp 3 9.2%、82.4%改善。
半導体商用(TSMC熊本工場戦略分析)—Groq 61.6%、Chirp 3 25.5%、58.6%改善。
半導体技術(TSMC 3nm、AI、地政学)—Groq 36.5%、Chirp 3 6.4%、82.4%改善。
商用会話(自己紹介、会議準備)—Groq 40.6%、Chirp 3 13.0%、68.0%改善。
平均すると:GroqのCERは47.8%、Chirp 3は13.5%。精度71.7%向上。
4つのシーン、Chirp 3が全勝。例外なし。
数字の背後にある鍵:単なるモデルの優秀さではなく「何を聞くべきかを知っている」
Chirp 3がこれほど勝利したのは、モデル自体がより強力だからだけではない。鍵は一つの機能にある:Speech Adaptation。
これはGoogle Cloud Speech-to-Textが提供する専門用語誘導メカニズムである。最大5,000個の「フレーズ」(phrases)を事前にモデルに与え、この会議にこれらの語彙が現れる可能性があるので優先的に認識してくださいと指示できる。
システムに約1,000個の日本語商用専門用語を入れた—「取引先」「発注書」「見積書」から「応急措置」「前年比」「稟議」まで。効果は即座に現れた:これらの語彙の適中率はほぼ100%である。
一方、Groq Whisperのpromptメカニズムは上限224 tokensで、約40個の専門用語しか入らない。しかもWhisperには悪名高い問題がある:無音部分で「幻覚」を起こし、prompt内容を直接認識結果として出力してしまう。
もう一つ見落とされがちな違い:セグメント長。Groqは5秒1セグメント、Chirp 3は15秒。5秒の文脈は短すぎ、モデルが途中で切れることが多く、文脈不足で誤判する。15秒はモデルが判断するのに十分な文脈を提供する。
この3つの要因の重ね合わせ—より強力な基礎モデル、1,000個の専門用語誘導、より長い文脈窓—が3倍の精度差を生み出した。
1回の会議1ドル未満
Chirp 3は無料ではない。課金方式は$0.016米ドル/分で、秒単位で課金される。
計算してみる:1時間の日本語商用会議でChirp 3のコストは$0.96米ドル。1ドル未満である。
月に20回日本語会議を開くなら、月額約$19米ドル、日本円換算で約624円。
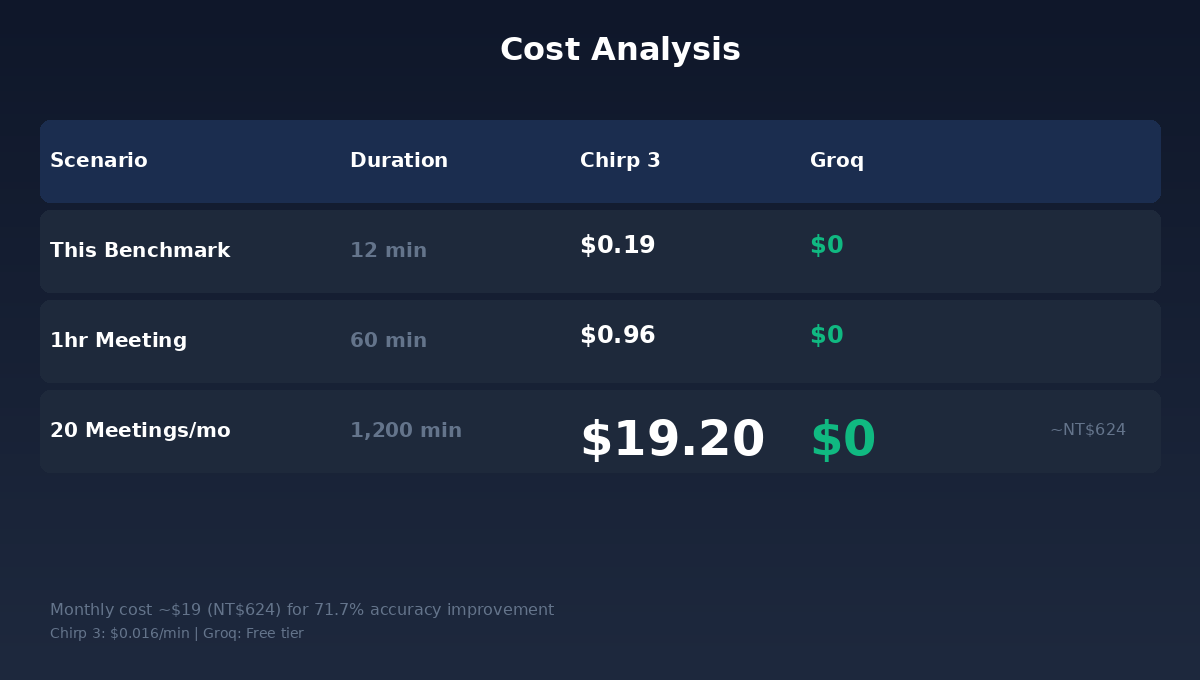
624円。得られるもの:日本のパートナーが言う全ての専門用語が正確に記録される;会議録の事後1時間の人工修正が不要;翻訳品質が「大意は分かる」から「逐字稿として直接使える」レベルに向上。
起業以来理解したこと:コミュニケーションのコストは、ツールにではなく誤解にある。 「納期」を一度聞き間違えて生じる納期遅延の代価は、1年分のChirp 3費用を遥かに上回る。
私の翻訳ツールでの現在の使用法
最後に技術面を補足する。現在のバージョンの翻訳ツールは「マルチパスルーティング」アーキテクチャを採用、つまり元言語と使用モードに基づいて異なる認識エンジンを自動切り替えする:
中国語はQwen(Aliの中国語ASRモデル、WebSocketストリーミング)、英語はGroq Whisper(無料・高速)、日本語一般モードもGroq、しかし日本語商用モードは自動的にGoogle Chirp 3に切り替わり、同時にユーザーの専門用語リストもSpeech Adaptationに送る。その他の言語はDeepgram Nova-3。
この設計の論理は非常にシンプルである:全てのシーンで最高精度が必要なわけではないが、商用シーンでは妥協できない。 Groqは無料・高速で、日常会話と非公式な場合に適している。Chirp 3は少し高く・遅い(15秒で1回返信)が、精度では別次元である。

「商用モード」ボタンを押すと、背後のルーティングが自動切り替わる—技術詳細を理解する必要はなく、このボタンを押せば日本語会議録が「だいたい合っている」から「ほぼ完全に合っている」に変わることを知るだけでよい。
精度は信頼の基盤
最初の問いに戻る:無料STTで十分か?
YouTube動画の日本語の大意を七八割理解し、大まかな内容が分かればそれでよいなら問題ない。しかし国際会議で相手が敬語を使って委婉に不満を表現しており、翻訳ツールが「ご立腹」を「ボディポップ」と聞き取った場合(冗談ではなく、実際の事例)—それでは全く不十分である。
音声認識の精度は抽象的な技術指標ではない。それはコミュニケーション連鎖の最も脆弱な環である。認識が間違えば翻訳も間違う;翻訳が間違えば決定も偏る。商用シーンでは、この鎖は信頼で繋がっている。
6.4%のエラー率は、100文字中6文字しか間違えないことを意味する。47.8%のエラー率は、ほぼ半分の内容が信頼できないことを意味する。
私は少し多めのToken費用を払っても、パートナーとの交流がより良い品質を保てることを確保したい。ただ、多くの方にとって日本語素材は必ずしもそこまで精密である必要がないことも理解している。人生は既に十分大変で、リラックスが必要な時は、自分をリラックスさせてよい。
専門用語集
- CER(Character Error Rate):文字エラー率。認識結果と正解の差異を測定、計算方式はLevenshtein編集距離を正解の文字数で除算。低いほど良く、0%は完璧を示す。
- STT(Speech-to-Text):音声テキスト変換技術。
- Ground Truth:比較用「正解」。本テストではYouTube自動生成日本語字幕を使用。
- Speech Adaptation:Google Cloud STTの機能。最大5,000個のフレーズを事前提供し、特定語彙の認識をモデルに誘導。
- Levenshtein Distance:編集距離。一つの文字列を別の文字列に変換するのに必要な最少操作回数(挿入、削除、置換)。
- Prompt:Whisperモデルのヒントテキスト(上限224 tokens)、認識方向の誘導に使用。Speech Adaptationに類似するが容量は遥かに少ない。
- RPM(Requests Per Minute):毎分リクエスト数、APIの速度制限。Groq無料プランは20 RPM。

💬 コメント
読み込み中...