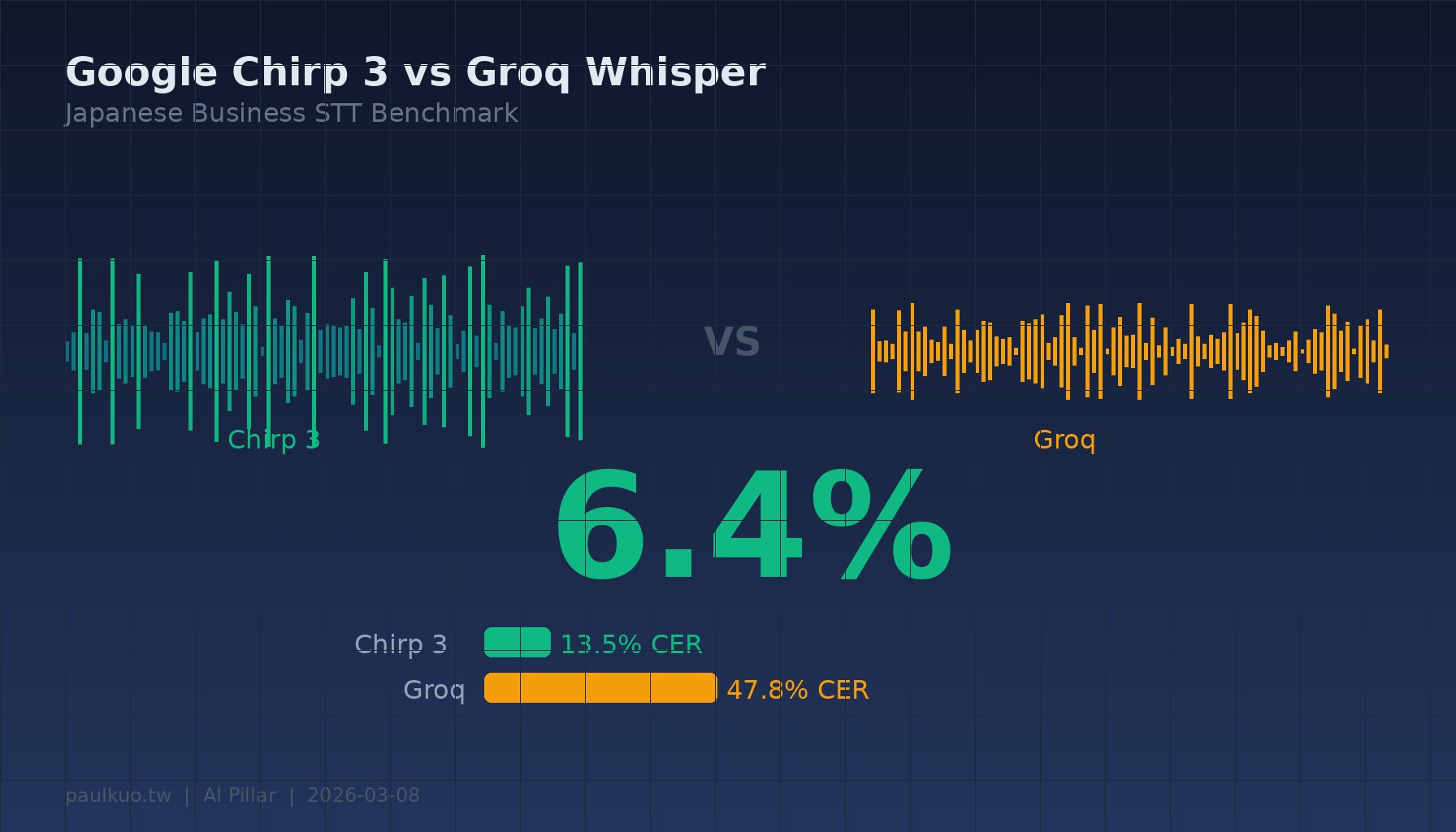
6.4%.
This is Google Chirp 3’s character error rate when recognizing a TSMC semiconductor technical explanation video. The same audio file fed to Groq Whisper yielded an error rate of 36.5%. One nearly word-perfect, the other missing every third word.
This wasn’t some carefully controlled lab experiment—just a random Japanese explanation video from YouTube, first three minutes, run through two engines. The gap in results was so large it made me rethink something fundamental: what exactly is our trust in “free AI tools” built upon?
Why I Ran This Test
I’ve been building a real-time meeting translation tool lately — an extension of becoming a super individual practitioner, using AI to accomplish what previously required a whole team. Technically straightforward — microphone input, speech recognition, real-time translation, subtitle display. But when actually used in Japanese business meetings, there’s a fatal flaw: recognition errors interfere with understanding.
“取引先” (business partner) becomes gibberish, “発注書” (purchase order) gets half-eaten, “ご指導のほど” (please provide guidance) gets heard as completely unrelated words. These aren’t occasional errors — they’re systematic architectural problems. And these terms happen to be the most critical terminology in business scenarios.
Originally I was using Groq’s free Whisper model. Fast, free, barely adequate for daily conversation, fine for casual “mm-hmm, ah-ah” content that makes people happy. But when your counterpart is a Japanese client and you’re translating a meeting about factory construction timelines and quality anomalies — “barely adequate” isn’t enough.
So I wanted to continue optimizing, aiming for higher benchmark standards, using data to answer: How much better is Chirp 3 really? Is it worth the cost?
Four Scenarios, Decisive Results
I selected four completely different types of Japanese videos, took the first three minutes of each, fed them to both engines, and calculated CER (Character Error Rate — simply the proportion of differences between recognition results and correct answers, lower is better) using YouTube’s auto-generated subtitles as ground truth.
Results:
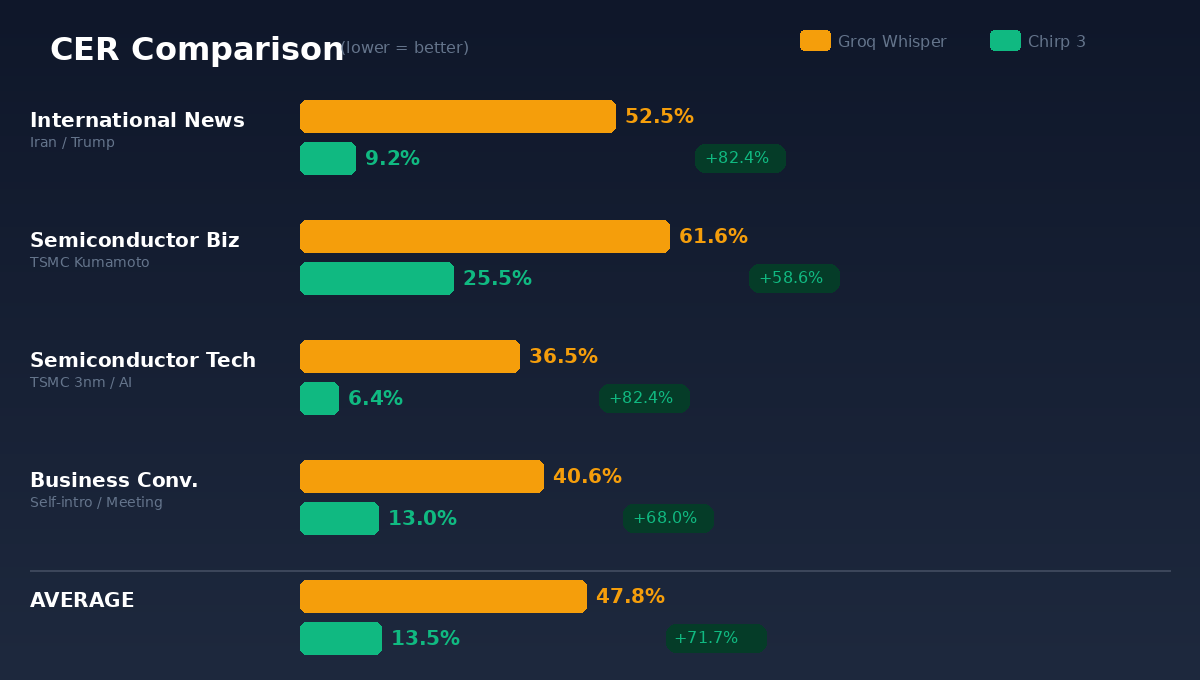
International News (PIVOT program: Trump’s Iran attack analysis) — Groq 52.5%, Chirp 3 9.2%, 82.4% improvement.
Semiconductor Business (TSMC Kumamoto factory strategy analysis) — Groq 61.6%, Chirp 3 25.5%, 58.6% improvement.
Semiconductor Technology (TSMC 3nm, AI, geopolitics) — Groq 36.5%, Chirp 3 6.4%, 82.4% improvement.
Business Conversation (self-introduction, meeting preparation) — Groq 40.6%, Chirp 3 13.0%, 68.0% improvement.
On average: Groq’s CER was 47.8%, Chirp 3’s was 13.5%. 71.7% accuracy improvement.
Four scenarios, Chirp 3 won across the board. No exceptions.
Behind the Numbers: Not Just Better Models, but “Knowing What to Listen For”
Chirp 3’s overwhelming victory isn’t just due to a stronger base model. The key lies in one feature: Speech Adaptation.
This is Google Cloud Speech-to-Text’s terminology guidance mechanism. You can pre-feed the model up to 5,000 “phrases,” telling it: this meeting might contain these words, please prioritize recognizing them.
I loaded about 1,000 Japanese business terms into the system — from “取引先” (business partner) “発注書” (purchase order) “見積書” (quotation) to “応急措置” (emergency measures) “前年比” (year-over-year) “稟議” (internal approval process). The effect was immediate: hit rate for these terms was nearly 100%.
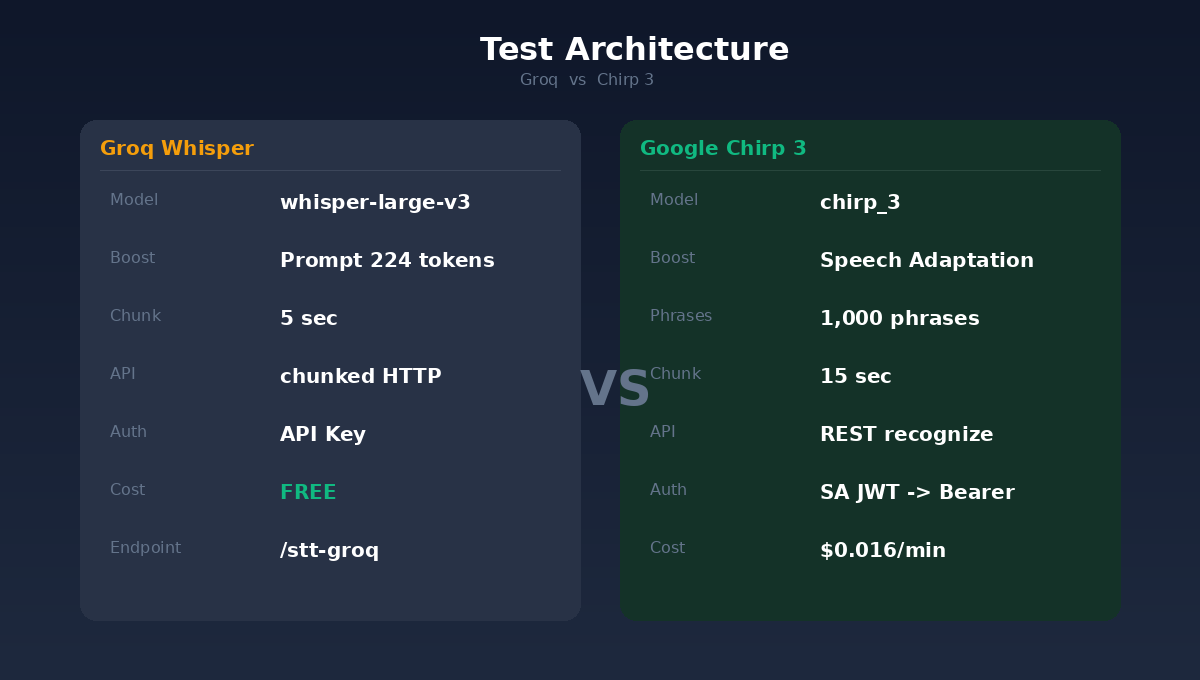
By contrast, Groq Whisper’s prompt mechanism has a limit of just 224 tokens, accommodating about 40 terms. And Whisper has a notorious problem: silent segments cause “hallucinations,” directly outputting prompt content as recognition results.
There’s another easily overlooked difference: chunk length. Groq uses 5-second segments, Chirp 3 uses 15 seconds. 5-second context is too short, causing the model to often cut off mid-sentence with insufficient context for accurate judgment. 15 seconds gives the model enough context for proper decisions.
These three factors combined — stronger base model, 1,000-term guidance, longer context window — created the triple accuracy gap.
Less Than One Dollar Per Meeting
Chirp 3 isn’t free. The billing model is $0.016 USD per minute, charged per second as the minimum unit.
Let’s calculate: a one-hour Japanese business meeting costs $0.96 USD with Chirp 3. Less than one dollar.
If you hold 20 Japanese meetings monthly, the monthly fee is about $19 USD, equivalent to NT$624.
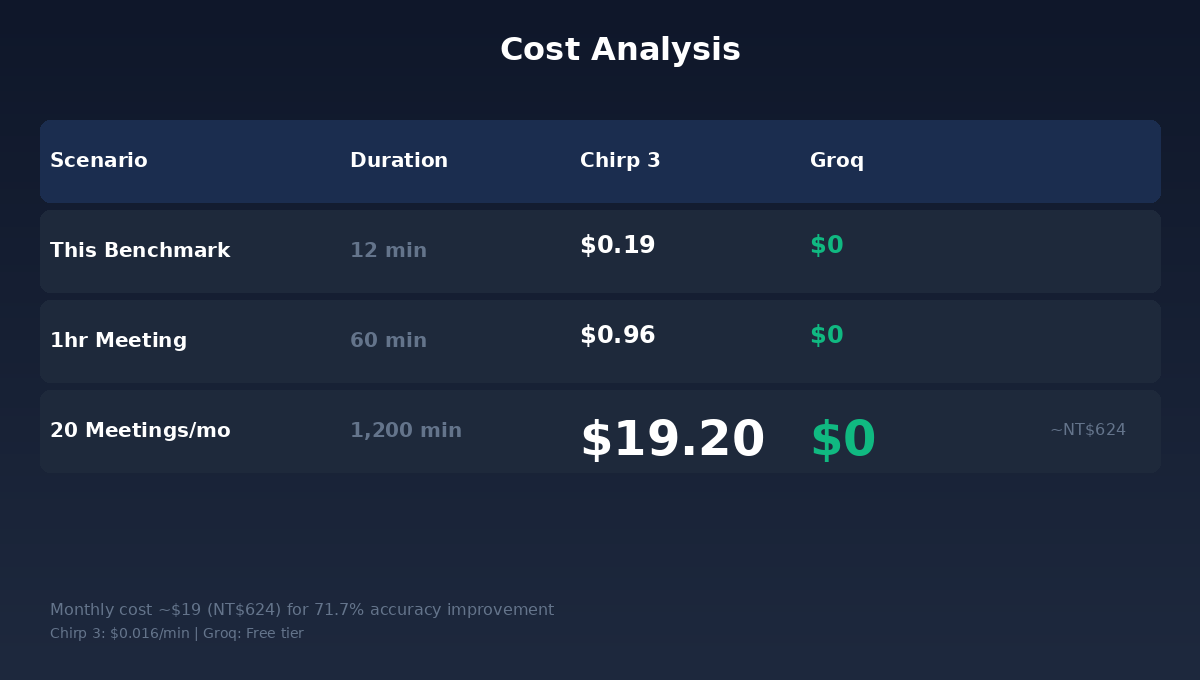
NT$624. In exchange for: every technical term your Japanese partners speak being correctly recorded; meeting minutes no longer requiring an hour of manual correction afterward; translation quality upgrading from “get the gist” to “usable as verbatim transcription.”
Through years of entrepreneurship, I’ve learned: communication costs never lie in tools — they lie in misunderstandings. One misheard “納期” (delivery date) causing schedule delays costs far more than a year of Chirp 3 fees.
How My Translation Tool Uses It Now
Let me add some technical details. The current version of my translation tool uses a “multi-path routing” architecture, meaning I automatically switch between different recognition engines based on source language and usage patterns:
Chinese goes to Qwen (Alibaba’s Chinese ASR model, WebSocket streaming), English goes to Groq Whisper (free, fast), Japanese in general mode also goes to Groq, but Japanese business mode automatically switches to Google Chirp 3, simultaneously feeding user terminology into Speech Adaptation. Other languages go to Deepgram Nova-3.
The logic behind this design is simple: not every scenario requires maximum accuracy, but business scenarios can’t compromise. Groq is free and fast, suitable for daily conversation and informal occasions. Chirp 3 is slightly more expensive and slower (returns results every 15 seconds), but operates at a different accuracy level.

When I press the “Business Mode” button, the routing automatically switches behind the scenes — no need to understand technical details, just know: turning this on transforms your Japanese meeting minutes from “roughly correct” to “nearly perfect.”
Accuracy as the Foundation of Trust
Back to the original question: is free STT sufficient?
If you just want to catch the gist of Japanese YouTube videos, understanding the general idea, that’s fine. But if you’re in a cross-border meeting where the other party is politely expressing dissatisfaction in keigo, and your translation tool hears “ご立腹” (anger) as “ボディポップ” (body pop) — I’m not joking, this is a real case — then it’s completely inadequate.
Speech recognition accuracy isn’t an abstract technical metric. It’s the most fragile link in the communication chain. Wrong recognition leads to wrong translation; wrong translation leads to skewed decisions. In business scenarios, this chain is held together by trust.
6.4% error rate means only 6 mistakes per 100 characters. 47.8% error rate means nearly half the content is unreliable.
I’d rather spend a bit more on token fees to ensure better quality communication with partners. Though I understand that for many people, Japanese content doesn’t necessarily require such precision. Life is hard enough already — when you need relaxed moments, allow yourself to relax.
Terminology
- CER (Character Error Rate): Character error rate. Measures differences between recognition results and correct answers, calculated as Levenshtein edit distance divided by correct answer character count. Lower is better, 0% represents perfection.
- STT (Speech-to-Text): Speech-to-text technology.
- Ground Truth: “Correct answers” used for comparison. This test used YouTube’s auto-generated Japanese subtitles.
- Speech Adaptation: Google Cloud STT feature allowing up to 5,000 pre-provided phrases to guide model recognition of specific vocabulary.
- Levenshtein Distance: Edit distance. Minimum number of operations (insert, delete, substitute) needed to transform one string into another.
- Prompt: Whisper model’s hint text (224 token limit), used to guide recognition direction. Functions similarly to Speech Adaptation but with much smaller capacity.
- RPM (Requests Per Minute): Requests per minute, API rate limiting. Groq’s free tier is 20 RPM.

💬 Comments
Loading...