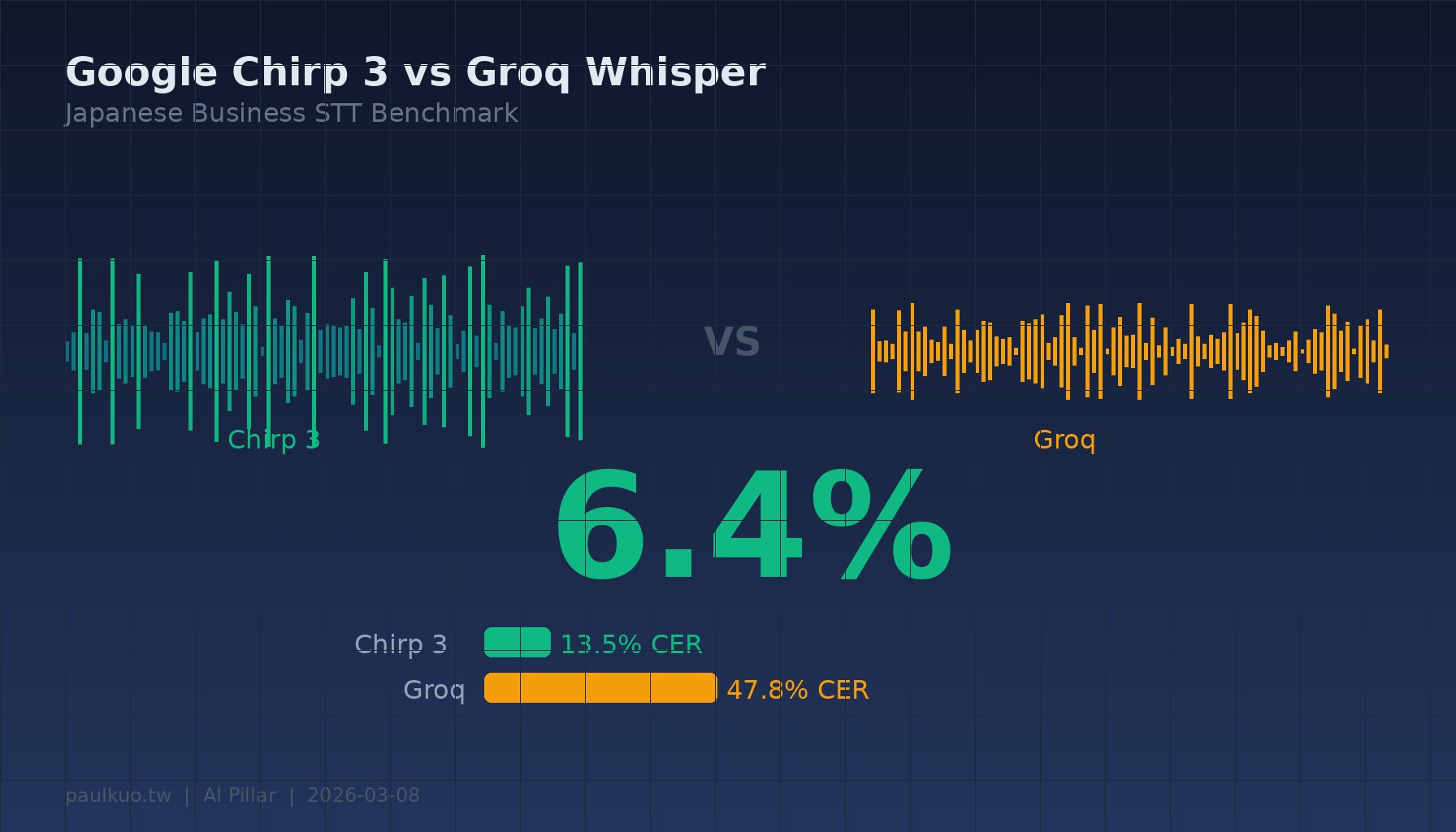
6.4%。
这是 Google Chirp 3 在识别一段 TSMC 半导体技术解说视频时的字符错误率。同一段音档丢给 Groq Whisper,错误率是 36.5%。一个几乎逐字正确,另一个每三个字就错一个。
这不是什么精心设计的实验室条件,就是 YouTube 上随便找的日文解说视频,前三分钟,切下来跑两个引擎。结果的差距,大到让我重新思考一件事:我们对「免费 AI 工具」的信任,到底建立在什么基础上?
为什么我要做这个测试
我最近在做一个即时会议翻译工具——算是成为超级个体实践的延伸,一个人用 AI 完成本来需要一个团队的事。技术上不复杂——麦克风收音、语音识别、即时翻译、字幕显示。但实际用在日文商务会议上,会有一个致命的问题:识别结果会干扰理解。
「取引先」变成乱码,「発注書」被吃掉一半,「ご指導のほど」被听成完全不相干的词。这些不是偶尔的错误——是架构设计的系统性问题。而这些词,恰恰是商务场景中最关键的术语。
原本用的是 Groq 提供的免费 Whisper 模型。速度快、不花钱,日常对话勉强能用,听听嗯嗯啊啊,让人开心的视频没问题。但若对方是日本客户,你正在翻译一场关于设厂时程和质量异常的会议——「勉强能用」就不够了。
所以我想继续优化,试着达标更高的 benchmark 检视,用数据来回答:Chirp 3 到底好多少?值不值得花那个钱?
四个场景,一面倒的结果
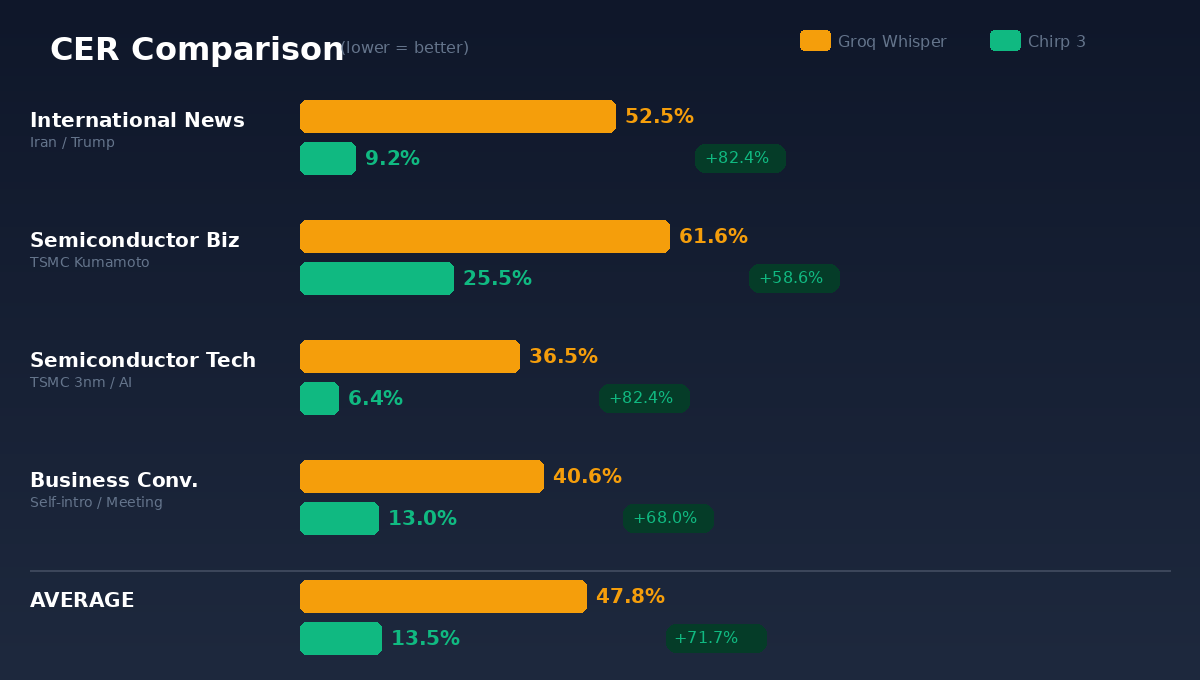
我挑了四段完全不同类型的日文视频,每段取前三分钟,分别送进两个引擎,以 YouTube 自动生成字幕为基准计算 CER(字符错误率,Character Error Rate——简单说就是识别结果跟正确答案之间的差异比例,越低越好)。
结果:
国际新闻(PIVOT 节目:川普攻击伊朗解说)——Groq 52.5%、Chirp 3 9.2%,改善 82.4%。
半导体商务(TSMC 熊本工厂战略分析)——Groq 61.6%、Chirp 3 25.5%,改善 58.6%。
半导体技术(TSMC 3nm、AI、地缘政治)——Groq 36.5%、Chirp 3 6.4%,改善 82.4%。
商务会话(自我介绍、会议准备)——Groq 40.6%、Chirp 3 13.0%,改善 68.0%。
平均下来:Groq 的 CER 是 47.8%,Chirp 3 是 13.5%。精准度提升 71.7%。
四个场景,Chirp 3 全胜。没有例外。
数字背后的关键:不只是模型好,是「知道该听什么」
Chirp 3 赢这么多,不只是因为模型本身更强。关键在一个功能:Speech Adaptation。
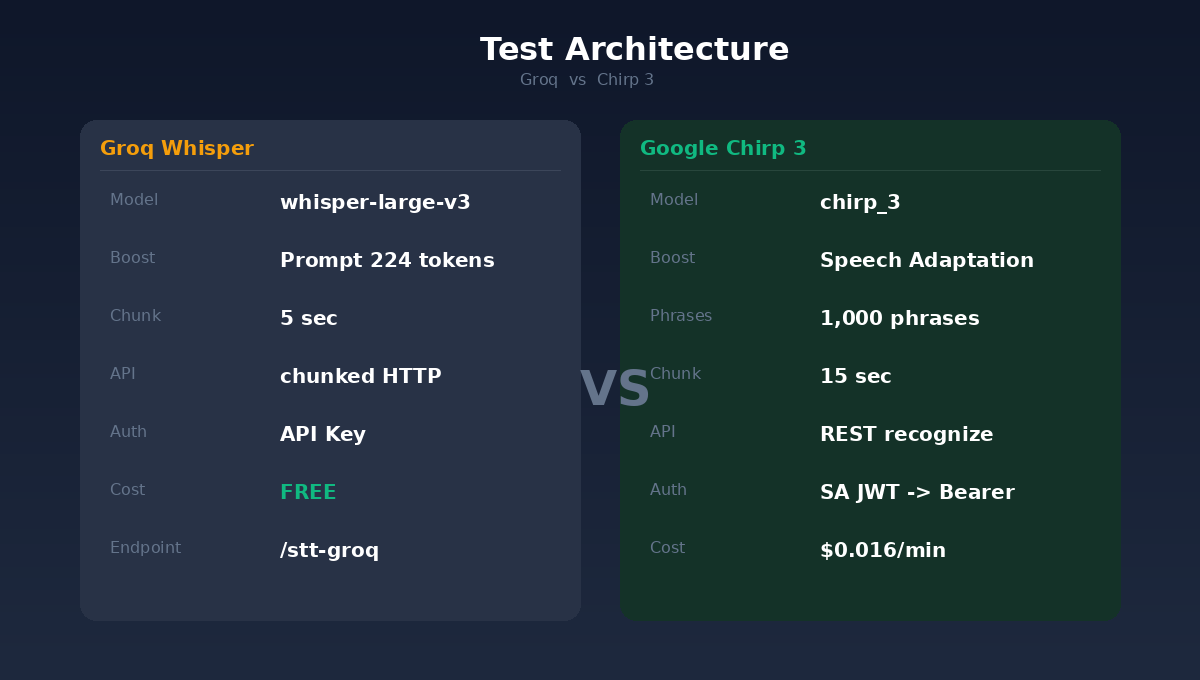
这是 Google Cloud Speech-to-Text 提供的术语引导机制。你可以预先喂给模型最多 5,000 个「短语」(phrases),告诉它:这场会议可能会出现这些词,请优先识别。
我让系统放了约 1,000 个日文商务术语进去——从「取引先」「発注書」「見積書」到「応急措置」「前年比」「稟議」。效果立竿见影:这些词的命中率几乎是 100%。
反观 Groq Whisper 的 prompt 机制,上限只有 224 tokens,大约塞得下 40 个术语。而且 Whisper 有个恶名昭彰的问题:静音段会「幻觉」,把 prompt 里的内容直接吐出来当识别结果。
还有一个容易被忽略的差异:切片长度。Groq 用 5 秒一段,Chirp 3 用 15 秒。5 秒的语境太短,模型经常听到一半就断了,上下文不足导致误判。15 秒则给了模型足够的语境去做判断。
这三个因素叠加——更强的基础模型、1,000 个术语引导、更长的语境窗口——造成了三倍的精准度差距。
一场会议不到一美元
Chirp 3 不是免费的。计费方式是 $0.016 美元/分钟,以秒为最小计费单位。
算一下:一场一小时的日文商务会议,Chirp 3 的成本是 $0.96 美元。不到一美元。
如果你每个月开 20 场日文会议,月费大约 $19 美元,折合新台币 624 元。
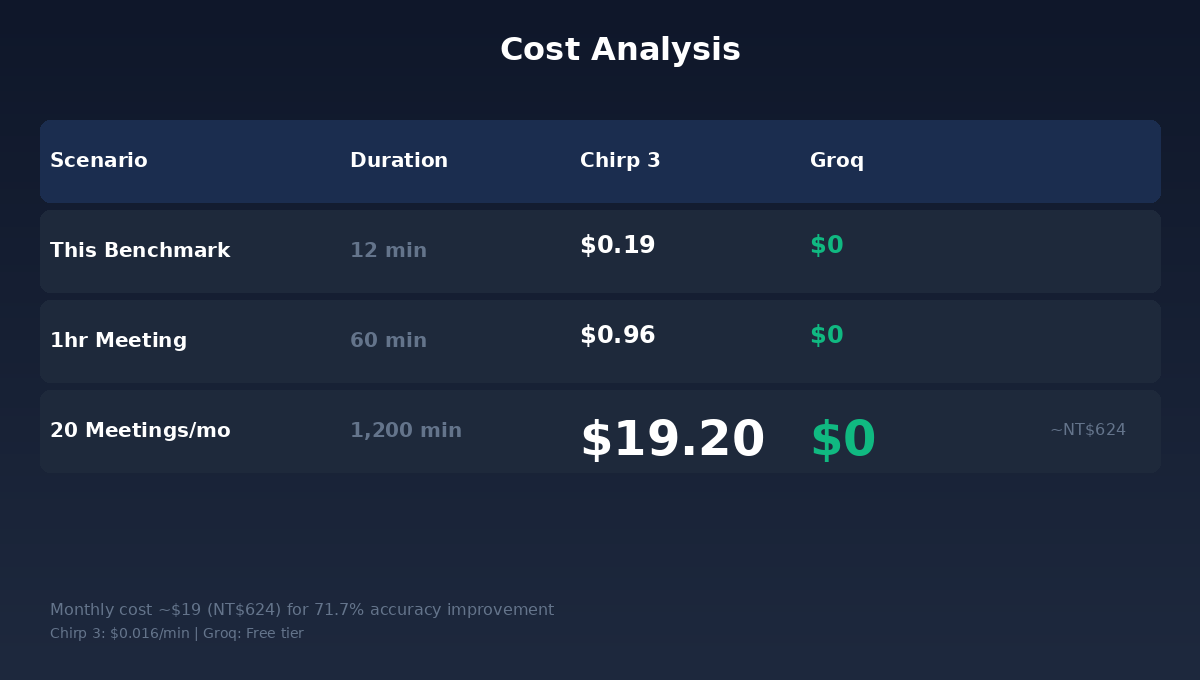
624 元。换取的是:日本伙伴说的每一个专业术语,都能正确记录下来;我们会议纪录可以不再需要事后花一小时人工修正;翻译质量从「看得懂大意」提升到「可以直接当逐字稿用」。
创业这些年,我理解到:沟通的成本,从来不在工具上——在误解上。 一次听错「納期」导致的交期延误,代价远超过一年的 Chirp 3 费用。
我的翻译工具现在怎么用它
最后补充一下技术面。目前这一版翻译工具采用「多路路由」架构,意思是,我根据来源语言和使用模式,自动切换不同的识别引擎:
中文走 Qwen(阿里的中文 ASR 模型,WebSocket 串流),英文走 Groq Whisper(免费、速度快),日文一般模式也走 Groq,但日文商务模式自动切换到 Google Chirp 3,同时把使用者的术语表词汇一起送进 Speech Adaptation。其他语言则走 Deepgram Nova-3。
这个设计的逻辑很简单:不是所有场景都需要最高精准度,但商务场景不能妥协。 Groq 免费、速度快,适合日常对话和非正式场合。Chirp 3 贵一点、慢一点(15 秒才回传一次),但在精准度上是另一个等级。

我按「商务模式」按钮,背后的路由就自动切换——不需要理解技术细节,只需要知道:开了这个按钮,你的日文会议纪录会从「大概对」变成「几乎完全对」。
精准度是信任的基础
回到最初的问题:免费 STT 够用吗?
如果只是想把 YouTube 视频的日文大意听个七七八八,知道大意那OK。但如果你在一场跨国会议里,对方正在用敬语委婉地表达不满,而翻译工具把「ご立腹」听成了「ボディポップ」(没有开玩笑,这是真实案例)——那就完全不够。
语音识别的精准度不是一个抽象的技术指标。它是沟通链条中最脆弱的一环。识别错了,翻译就错了;翻译错了,决策就偏了。在商务场景里,这条链是用信任串起来的。
6.4% 的错误率,意味着每 100 个字只错 6 个。47.8% 的错误率,意味着将近一半的内容不可靠。
我宁愿多花一点 Token 费用,也希望确保与伙伴之间的交流能维持更好的质量。不过我也理解,对很多朋友来说,日语素材其实不一定需要那么精准。人生已经够不容易了,需要轻松一点的时刻,就让自己轻松一点。
术语表
- CER(Character Error Rate):字符错误率。衡量识别结果与正确答案的差异,计算方式是 Levenshtein 编辑距离除以正确答案的字数。越低越好,0% 代表完美。
- STT(Speech-to-Text):语音转文字技术。
- Ground Truth:用于比对的「正确答案」。本测试使用 YouTube 自动生成的日文字幕。
- Speech Adaptation:Google Cloud STT 的功能,允许预先提供最多 5,000 个短语引导模型识别特定词汇。
- Levenshtein Distance:编辑距离。将一个字符串转换成另一个字符串所需的最少操作次数(插入、删除、替换)。
- Prompt:Whisper 模型的提示文字(上限 224 tokens),用于引导识别方向。功能类似 Speech Adaptation,但容量小得多。
- RPM(Requests Per Minute):每分钟请求数,API 的速率限制。Groq 免费方案为 20 RPM。

💬 留言讨论
加载中...